

The Single Responsibility (SRP), Open/Closed (OCP), Liskov Substitution, Interface Segregation, and Dependency Inversion. Five agile principles that should guide you every time you write code.
It would be unjust to tell you that any one of the SOLID principles is more important than another. However, probably none of the others have such an immediate and profound effect on your code than the Dependency Inversion Principle, or DIP in short. If you find the other principles hard to grasp or apply, start with this one and apply the rest on code that already respects DIP.
Definition
A. High-level modules should not depend on low-level modules. Both should depend on abstractions.
B. Abstractions should not depend upon details. Details should depend upon abstractions.
This principle was defined by Robert C. Martin in his book Agile Software Development, Principles, Patterns, and Practices and later republished in the C# version of the book Agile Principles, Patterns, and Practices in C#, and it is the last of the five SOLID agile principles.
DIP in the Real World
Before we start coding, I would like to tell you a story. At Syneto, we weren't always so careful with our code. A few years ago we knew less and even though we tried to do our best, not all of our projects were so nice. We went through hell and back again and we learned many things by trial and error.
The SOLID principles and the clean architecture principles of Uncle Bob (Robert C. Martin) became a game changer for us and transformed our way of coding in ways that are hard to describe. I will try to exemplify, in a nutshell, a few key architectural decisions imposed by DIP that had a great impact on our projects.
Most web projects contain three main technologies: HTML, PHP, and SQL. The particular version of these applications we are talking about or what type of SQL implementations you use is irrelevant. The thing is, that information from an HTML form must end up, in one way or another, in the database. The glue between the two can be provided with PHP.
What is essential to take away from this, is that how nicely the three technologies represent three different architectural layers: user interface, business logic, and persistence. We will talk about the implications of these layers in a minute. For now, let's focus on some odd but frequently encountered solutions to make the technologies work together.
Many times I've seen projects that used SQL code in a PHP tag inside an HTML file, or PHP code echoing pages and pages of HTML and interpreting directly the $_GET or $_POST global variables. But why is this bad?
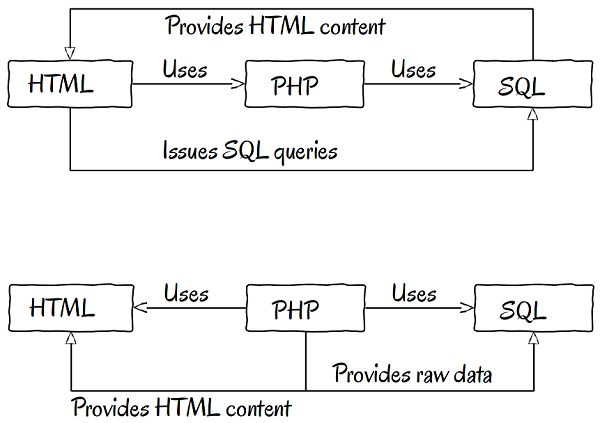
The images above represent a raw version of what we described in the previous paragraph. The arrows represent various dependencies, and as we can conclude, basically everything depends on everything. If we need to change a database table, we may end up editing an HTML file. Or if we change a field in HTML, we may end up changing the name of a column in an SQL statement. Or if we look at the second schema, we may very well need to modify our PHP if the HTML changes, or in very bad cases, when we generate all HTML content from inside a PHP file we will surely need to change a PHP file to modify HTML content. So, there is no doubt, the dependencies are zigzagging between the classes and modules. But it doesn't end here. You can store procedures; PHP code in SQL tables.
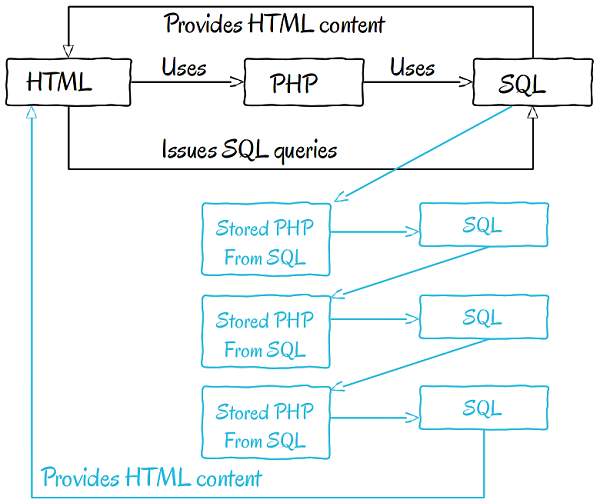
In the schema above, queries to the SQL database return PHP code generated with data from the tables. These PHP functions or classes are doing other SQL queries which are returning different PHP code, and the cycle continues until finally all the information is obtained and returned... probably to the UI.
I know this may sound outrageous to many of you, but if you have not yet worked with a project invented and implemented in this manner, you surely will in your future career. Most existing projects, regardless of the programming languages used, were written with old principles in mind, by programmers who did not care or know enough to do better. If you are reading these tutorials, you are most likely a level higher than that. You are ready, or getting ready to respect your profession, to embrace your craft, and to do better.
The other option is to repeat the mistakes your predecessors made and live with the consequences. At Syneto, after one of our projects reached an almost unmaintainable state because of its old and cross-dependent architecture and we had to basically abandon it forever, we decided to never go back down that road again. Since then, we have striven to have a clean architecture which correctly respects the SOLID principles, and most importantly the Dependency Inversion Principle.


What's so amazing about this architecture is how the dependencies are pointing:
- The user interface (in most cases a web MVC framework) or whatever other delivery mechanism there is for your project will depend on the business logic. Business logic is quite abstract. A user interface is very concrete. The UI is just a detail for the project, and it is also very volatile. Nothing should depend on the UI, nothing should depend on your MVC framework.
- The other interesting observation we can make is that the persistence, the database, your MySQL or PostgreSQL, depends on the business logic. Your business logic is database agnostic. This allows exchanging persistence as you wish. If tomorrow you want to change MySQL with PostgreSQL or just plain text files, you can do that. You will, of course, need to implement a specific persistence layer for the new persistence method, but you will not need to modify a single line of code in your business logic. There is a more detailed explanation on the persistence topic in the Evolving Toward a Persistence Layer tutorial.
- Finally, on the right of the business logic, outside of it, we have all the classes that are creating business logic classes. These are factories and classes created by the entry point to our application. Many people tend to think these belong to the business logic, but while they are creating business objects, their sole reason is to do this. They are classes just to help us create other classes. The business objects and the logic they provide are independent of these factories. We could use different patterns, like Simple Factory, Abstract Factory, Builder or plain object creation to provide the business logic. It doesn't matter. Once the business objects are created they can do their job.
Show Me the Code
Applying the Dependency Inversion Principle (DIP) at an architectural level is quite easy if you respect the classic agile design patterns. Exercising and exemplifying it inside the business logic is quite easy also and can even be fun. We will imagine an e-book reader application.
1 |
class Test extends PHPUnit_Framework_TestCase { |
2 |
|
3 |
function testItCanReadAPDFBook() { |
4 |
$b = new PDFBook(); |
5 |
$r = new PDFReader($b); |
6 |
|
7 |
$this->assertRegExp('/pdf book/', $r->read()); |
8 |
}
|
9 |
|
10 |
}
|
11 |
|
12 |
class PDFReader { |
13 |
|
14 |
private $book; |
15 |
|
16 |
function __construct(PDFBook $book) { |
17 |
$this->book = $book; |
18 |
}
|
19 |
|
20 |
function read() { |
21 |
return $this->book->read(); |
22 |
}
|
23 |
|
24 |
}
|
25 |
|
26 |
class PDFBook { |
27 |
|
28 |
function read() { |
29 |
return "reading a pdf book."; |
30 |
}
|
31 |
}
|
We start developing our e-reader as a PDF reader. So far so good. We have a PDFReader class using a PDFBook. The read() function on the reader delegates to the book's read() method. We just verify this by doing a regex check after a key part of the string returned by PDFBook's reader() method.
Please bear in mind that this is just an example. We will not implement the reading logic of PDF files or other file formats. That's why our tests will just simply check for some basic strings. If we were to write the real application, the only difference would be how we test the different file formats. The dependency structure would be very similar to our example.

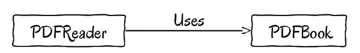
Having a PDF reader using a PDF book may be a sound solution for a limited application. If our scope was to write a PDF reader and nothing more, it would actually be an acceptable solution. But we want to write a generic e-book reader, supporting several formats, amongst which our first implemented version PDF. Let's rename our reader class.
1 |
class Test extends PHPUnit_Framework_TestCase { |
2 |
|
3 |
function testItCanReadAPDFBook() { |
4 |
$b = new PDFBook(); |
5 |
$r = new EBookReader($b); |
6 |
|
7 |
$this->assertRegExp('/pdf book/', $r->read()); |
8 |
}
|
9 |
|
10 |
}
|
11 |
|
12 |
class EBookReader { |
13 |
|
14 |
private $book; |
15 |
|
16 |
function __construct(PDFBook $book) { |
17 |
$this->book = $book; |
18 |
}
|
19 |
|
20 |
function read() { |
21 |
return $this->book->read(); |
22 |
}
|
23 |
|
24 |
}
|
25 |
|
26 |
class PDFBook { |
27 |
|
28 |
function read() { |
29 |
return "reading a pdf book."; |
30 |
}
|
31 |
}
|
Renaming had no functional counter effects. The tests are still passing.
Testing started at 1:04 PM ...
PHPUnit 3.7.28 by Sebastian Bergmann.
Time: 13 ms, Memory: 2.50Mb
OK (1 test, 1 assertion)
Process finished with exit code 0
But it has a serious design effect.


Our reader became much more abstract. Much more general. We have a generic EBookReader that uses a very specific book type, PDFBook. An abstraction depends on a detail. The fact that our book is of type PDF should only be a detail, and no one should depend on it.
1 |
class Test extends PHPUnit_Framework_TestCase { |
2 |
|
3 |
function testItCanReadAPDFBook() { |
4 |
$b = new PDFBook(); |
5 |
$r = new EBookReader($b); |
6 |
|
7 |
$this->assertRegExp('/pdf book/', $r->read()); |
8 |
}
|
9 |
|
10 |
}
|
11 |
|
12 |
interface EBook { |
13 |
function read(); |
14 |
}
|
15 |
|
16 |
class EBookReader { |
17 |
|
18 |
private $book; |
19 |
|
20 |
function __construct(EBook $book) { |
21 |
$this->book = $book; |
22 |
}
|
23 |
|
24 |
function read() { |
25 |
return $this->book->read(); |
26 |
}
|
27 |
|
28 |
}
|
29 |
|
30 |
class PDFBook implements EBook{ |
31 |
|
32 |
function read() { |
33 |
return "reading a pdf book."; |
34 |
}
|
35 |
}
|
The most common, and most frequently used solution to invert the dependency is to introduce a more abstract module in our design. "The most abstract element in OOP is an Interface. Thus, any other class can depend on an Interface and still respect DIP".
We created an interface for our reader. The interface is called EBook and represents the needs of the EBookReader. This is a direct result of respecting the Interface Segregation Principle (ISP) which promotes the idea that interfaces should reflect the needs of the clients. Interfaces belong to the clients, and thus they are named to reflect the types and objects the clients need and they will contain methods the clients wants to use. It is only natural for an EBookReader to use EBooks and have a read() method.
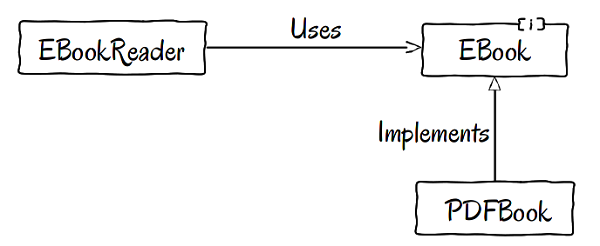
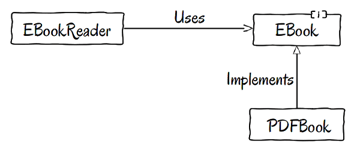
Instead of a single dependency, we have two dependencies now.
- The first dependency points from
EBookReadertoward theEBookinterface and it is of type usage.EBookReaderusesEBooks. - The second dependency is different. It points from
PDFBooktoward the sameEBookinterface but it is of type implementation. APDFBookis just a particular form ofEBook, and thus implements that interface to satisfy the client's needs.
Unsurprisingly, this solution also allows us to plug in different types of ebooks into our reader. The single condition for all these books is to satisfy the EBook interface and implement it.
1 |
class Test extends PHPUnit_Framework_TestCase { |
2 |
|
3 |
function testItCanReadAPDFBook() { |
4 |
$b = new PDFBook(); |
5 |
$r = new EBookReader($b); |
6 |
|
7 |
$this->assertRegExp('/pdf book/', $r->read()); |
8 |
}
|
9 |
|
10 |
function testItCanReadAMobiBook() { |
11 |
$b = new MobiBook(); |
12 |
$r = new EBookReader($b); |
13 |
|
14 |
$this->assertRegExp('/mobi book/', $r->read()); |
15 |
}
|
16 |
|
17 |
}
|
18 |
|
19 |
interface EBook { |
20 |
function read(); |
21 |
}
|
22 |
|
23 |
class EBookReader { |
24 |
|
25 |
private $book; |
26 |
|
27 |
function __construct(EBook $book) { |
28 |
$this->book = $book; |
29 |
}
|
30 |
|
31 |
function read() { |
32 |
return $this->book->read(); |
33 |
}
|
34 |
|
35 |
}
|
36 |
|
37 |
class PDFBook implements EBook { |
38 |
|
39 |
function read() { |
40 |
return "reading a pdf book."; |
41 |
}
|
42 |
}
|
43 |
|
44 |
class MobiBook implements EBook { |
45 |
|
46 |
function read() { |
47 |
return "reading a mobi book."; |
48 |
}
|
49 |
}
|
Which in turn leads us to The Open/Closed Principle, and the circle is closed.
The Dependency Inversion Principle is one that leads or helps us respect all the other principles. Respecting DIP will:
- Almost force you into respecting OCP.
- Allow you to separate responsibilities.
- Make you correctly use subtyping.
- Offer you the opportunity to segregate your interfaces.
Final Thoughts
That's it. We are done. All tutorials about the SOLID principles are complete. For me, personally, discovering these principles and implementing projects with them in mind was a huge change. I completely changed the way I think about design and architecture and I can say since then all the projects I work on are exponentially easier to manage and understand.
I consider the SOLID principles one of the most essential concepts of object-oriented design. These concepts that must guide us in making our code better and our life as programmers much much easier. Well-designed code is easier for programmers to understand. Computers are smart, they can understand code regardless of its complexity. Human beings on the other hand have a limited number of things they can keep in their active, focused mind. More specifically, the number of such things is The Magical Number Seven, Plus or Minus Two.
We should strive to have our code structured around these numbers and there are several techniques that help us do so. Functions with a maximum of four lines in length (five with the definition line included) so that they can all fit at once within our mind. Indentations not passing five levels deep. Classes with no more than nine methods. Design patterns that usually use a number of five to nine classes. Our high level design in the schemas above uses four to five concepts. There are five SOLID principles, each requiring five to nine sub-concepts/modules/classes to be exemplified. The ideal size of a programming team is between five and nine. The ideal number of teams in a company is between five and nine.
As you can see, the magical number seven, plus or minus two is all around us, so why should your code be different?
 By
By









