

If you need to parse HTML, regular expressions aren't the way to go. In this tutorial, you'll learn how to use an open-source, easily learned parser to read, modify, and spit back out HTML from external sources. Using Envato Tuts+ as an example, you'll learn how to get a list of all the articles published on the site and display them.
1. Preparation
The first thing to do is to install Composer, which allows you to easily install PHP packages.
Next, create a new folder, open a terminal inside that folder, and run composer init in the terminal. Then, go through the dialog with responses like this:

The two important parts are to select project as the type, and add voku/simple_html_dom as a dependency. You can configure the rest however you want.
Finally, create a file in the directory called simple_html_dom.php and put the following in the file:
1 |
<?php
|
2 |
|
3 |
use voku\helper\HtmlDomParser; |
4 |
|
5 |
require_once 'composer/autoload.php'; |
6 |
2. Parsing Basics
This library is very easy to use, but there are some basics you should review before putting it into action.
Loading HTML
1 |
// Load from a string
|
2 |
$dom = HtmlDomParser::str_get_html('<html><body><p>Hello World!</p><p>We\'re here</p></body></html>'); |
3 |
// Load from a file or URL
|
4 |
$dom = HtmlDomParser::file_get_html('https://bbc.com'); |
You can create your initial object by loading HTML either from a string or from a file. Loading a file can be done either via URL or via your local file system.
Accessing Information
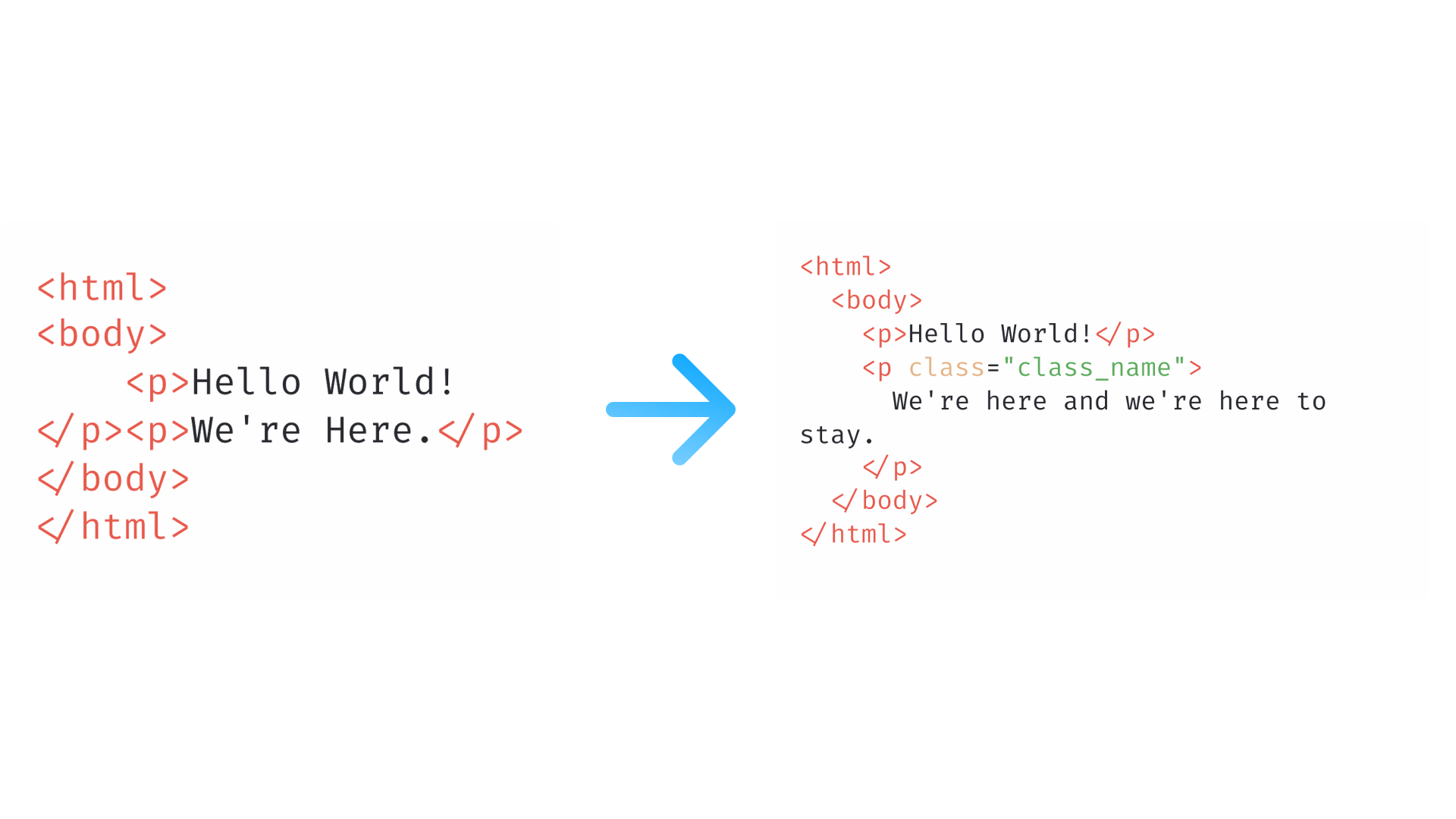
Once you have your DOM object, you can start to work with it by using find() and creating collections. A collection is a group of objects found via a selector—the syntax is quite similar to jQuery.
1 |
<html>
|
2 |
<body>
|
3 |
<p>Hello World!</p> |
4 |
<p>We're Here.</p> |
5 |
</body>
|
6 |
</html>
|
In this example HTML, we're going to take a look at how to access the information in the second paragraph, change it, and then output the results.
1 |
// create & load the HTML
|
2 |
$dom = HtmlDomParser::str_get_html("<html><body><p>Hello World!</p><p>We're here</p></body></html>"); |
3 |
// get all paragraph elements
|
4 |
$element = $dom->find("p"); |
5 |
// modify the second
|
6 |
$element[1]->innerText .= " and we're here to stay."; |
7 |
// print it
|
8 |
echo $dom->save(); |
Using the find() method always returns a collection (array) of tags unless you specify that you only want the nth child, as a second parameter.
First we load the HTML from a string, as explained previously.
The find method call finds all <p> tags in the HTML and returns them as an array. The first paragraph will have an index of 0, and subsequent paragraphs will be indexed accordingly.
Finally, we access the second item in our collection of paragraphs (index 1) and make an addition to its innertext attribute. innertext represents the contents between the tags, while outertext represents the contents including the tag. We could replace the tag entirely by using outertext.
We're going to add one more line and modify the class of our second paragraph tag.
1 |
$element[1]->class = "class_name"; |
2 |
echo $dom->save(); |
The resulting HTML of the save command would be:
1 |
<html>
|
2 |
<body>
|
3 |
<p>Hello World!</p> |
4 |
<p class="class_name">We're here and we're here to stay.</p> |
5 |
</body>
|
6 |
</html>
|
Other Selectors
Here are some other examples of selectors. If you've used jQuery, these will seem very familiar.
1 |
// get the first occurrence of id="foo"
|
2 |
$single = $dom->find('//foo', 0); |
3 |
// get all elements with class="foo"
|
4 |
$collection = $dom->find('.foo'); |
5 |
// get all the anchor tags on a page
|
6 |
$collection = $dom->find('a'); |
7 |
// get all anchor tags that are inside H1 tags
|
8 |
$collection = $dom->find('h1 a'); |
9 |
// get all img tags with a title of 'himom'
|
10 |
$collection = $dom->find('img[title=himom]'); |
The first example isn't entirely intuitive—all queries by default return collections, even an ID query, which should only return a single result. However, by specifying the second parameter, we are saying "only return the first item of this collection". This means $single is a single element, rather than an array of elements with one item.
The rest of the examples are self-explanatory.
Documentation
Complete documentation on the library can be found at the official project GitHub.
3. A Real-World Example
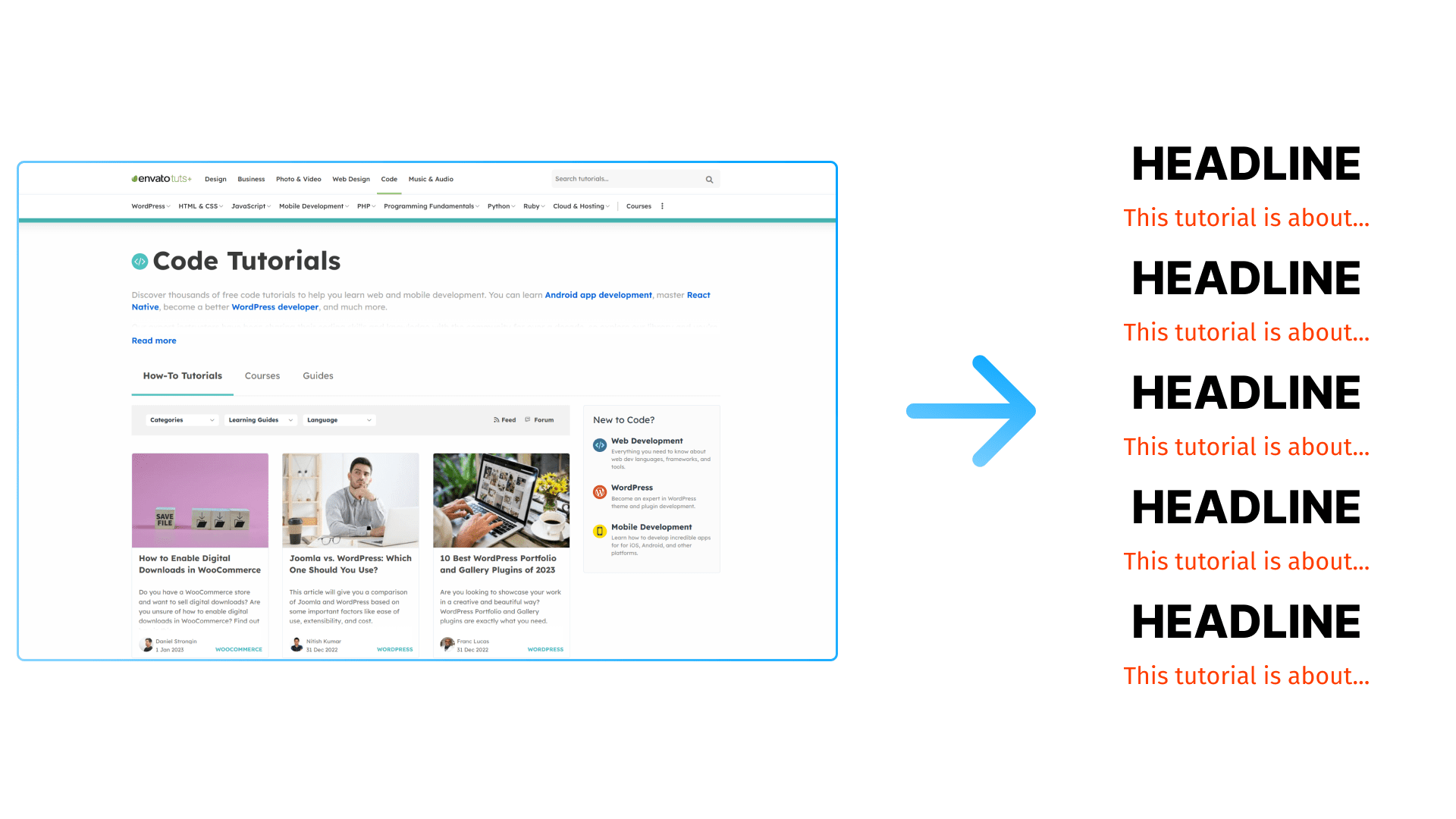
To put this library into action, we're going to write a quick script to scrape the contents of the Envato Tuts+ website and produce a list of articles present on the site by title and description... only as an example.
1 |
use voku\helper\HtmlDomParser; |
2 |
require_once 'vendor/autoload.php'; |
3 |
|
4 |
$articles = array(); |
5 |
getArticles('https://code.tutsplus.com/tutorials'); |
We start by including the library and calling the getArticles function with the page we'd like to start parsing. In this case, we're starting near the end and being kind to Tuts+'s server.
We're also declaring a global array to make it simple to gather all the article information in one place. Before we begin parsing, let's take a look at how an article summary is described on Tuts+.
1 |
<article>
|
2 |
<header>...</header> |
3 |
<div class="posts__post-teaser">...</div> |
4 |
<footer class="posts__post-details"> |
5 |
<div class="posts__post-teaser-overlay"></div> |
6 |
<div class="posts__post-publication-meta"> |
7 |
... |
8 |
<div class="posts__post-details__info"> |
9 |
<address class="posts__post-author">...</address> |
10 |
<time class="posts__post-publication-date">...</time> |
11 |
</div>
|
12 |
</div>
|
13 |
<div class="posts__post-primary-category"> |
14 |
<a class="posts__post-primary-category-link topic-code" href="">...</a> |
15 |
</div>
|
16 |
</footer>
|
17 |
</article>
|
This represents a basic post format on the site, including source code comments. Why are the comments important? They count as nodes to the parser.
4. Starting the Parsing Function
1 |
function getArticles($page) { |
2 |
global $articles; |
3 |
$html = HtmlDomParser::file_get_html($page); |
4 |
...
|
5 |
}
|
We begin by getting the global variable $articles and loading the page into Simple HTML DOM using file_get_html, as we have done previously. $page is the URL we passed in earlier.
5. Finding the Information We Want
1 |
$items = $html->find('article'); |
2 |
foreach($items as $post) { |
3 |
$articles[] = array(/* get title */ $post->findOne(".posts__post-title")->firstChild()->text(), |
4 |
/* get description */ $post->findOne("posts__post-teaser")->text()); |
5 |
}
|
This is the meat of the getArticles function. It's going to take a closer look to really understand what's happening.
First we create an array of elements—divs with the class of preview. We now have a collection of articles stored in $items.
In the foreach block, $post now refers to a single div of class preview. If we look at the original HTML, we can see that the title of the post is contained in the first child of posts__post-title. Therefore, to get the title, we take the text of that element.
The description is contained in posts_post-title. We take the text out of that element and put in the second element in the article item. A single record in articles now looks like this:
1 |
$articles[0][0] = "My Article Name Here"; |
2 |
$articles[0][1] = "This is my article description" |
6. Pagination
The first thing we do is determine how to find our next page. On Tuts+, the URLs are easy to figure out, but we're going to pretend they aren't and get the next link via parsing.
If we look at the HTML, we see the following:
1 |
<a rel="next" class="pagination__button pagination__next-button" aria-label="next" href="/tutorials?page=2"><i class="fa fa-angle-right"></i></a> |
If there is a next page (and there won't always be), we'll find an anchor with the class of nextpostslink. Now that information can be put to use.
1 |
if($next = $html->find('a[class=pagination__next-button]', 0)) { |
2 |
$URL = $next->href; |
3 |
$html->clear(); |
4 |
unset($html); |
5 |
getArticles($URL); |
6 |
}
|
On the first line, we see if we can find an anchor with the class pagination__next-button. Take special notice of the second parameter for find(). This specifies that we only want the first element (index 0) of the found collection returned. $next will only be holding a single element, rather than a group of elements.
Next, we assign the link's href to the variable $URL. This is important because we're about to destroy the HTML object. Due to a PHP circular references memory leak, $html must be cleared and unset before another one is created. Failure to do so could cause you to eat up all your available memory.
Finally, we call getArticles with the URL of the next page. This recursion ends when there are no more pages to parse.
You are done with the scraping! This is how the final code should look:
1 |
<?php
|
2 |
use voku\helper\HtmlDomParser; |
3 |
require_once 'vendor/autoload.php'; |
4 |
|
5 |
$articles = array(); |
6 |
getArticles('https://code.tutsplus.com/tutorials'); |
7 |
|
8 |
function getArticles($page) { |
9 |
global $articles; |
10 |
$html = HtmlDomParser::file_get_html($page); |
11 |
$items = $html->find('article'); |
12 |
foreach($items as $post) { |
13 |
$articles[] = array(/* get title */ $post->findOne(".posts__post-title")->firstChild()->text(), |
14 |
/* get description */ $post->findOne("posts__post-teaser")->text()); |
15 |
}
|
16 |
if($next = $html->find('a[class=pagination__next-button]', 0)) { |
17 |
$URL = $next->href; |
18 |
$html->clear(); |
19 |
unset($html); |
20 |
getArticles($URL); |
21 |
}
|
22 |
}
|
7. Outputting the Results
First, we're going to set up a few basic styles. This is completely arbitrary—you can make your output look however you wish.

1 |
#main { |
2 |
margin:80px auto; |
3 |
width:500px; |
4 |
}
|
5 |
h1 { |
6 |
font:bold 40px/38px helvetica, verdana, sans-serif; |
7 |
margin:0; |
8 |
}
|
9 |
h1 a { |
10 |
color:#600; |
11 |
text-decoration:none; |
12 |
}
|
13 |
p { |
14 |
background: #ECECEC; |
15 |
font:10px/14px verdana, sans-serif; |
16 |
margin:8px 0 15px; |
17 |
border: 1px #CCC solid; |
18 |
padding: 15px; |
19 |
}
|
20 |
.item { |
21 |
padding:10px; |
22 |
}
|
Next, we're going to put a bit of PHP in the page to output the previously stored information.
1 |
<?php
|
2 |
foreach($articles as $item) { |
3 |
echo "<div class='item'>"; |
4 |
echo $item[0]; |
5 |
echo $item[1]; |
6 |
echo "</div>"; |
7 |
}
|
8 |
?>
|
The final result is a single HTML page listing all the articles, starting on the page indicated by the first getArticles() call.
Conclusion
If you're parsing many pages (say, the entire site), it may take longer than the maximum execution time allowed by your server. For example, running from my local machine it takes about one second per page (including time to fetch). On large sites like Envato Tuts+, this could take an extremely long time.
This tutorial should get you started with HTML parsing. There are other methods to work with the DOM, including PHP's built-in one, which lets you work with powerful xpath selectors to find elements. But for ease of use, and quick starts, I find this library to be one of the best.
As a closing note, always remember to obtain permission before scraping a site: this is important. Thanks for reading!
 By
By









