


Regular expressions are a language of their own. Today, we'll review nine regular expressions that you should know for your next coding project.
For a refresher on regular expressions, check out our regex cheat sheet.




What Is a Regular Expression?
Regular expressions (also known as regex) are a concise and flexible way to search and replace within text strings. With a regular expression, you can easily match characters, words, or patterns within text. A really basic example would be the regex /c*t/—this would match "cat", "cot", or "cut", but not "pat" or "but".
The regular expressions I'll show you today will allow you to match:
- a username
- a password
- a hex value
- a slug
- an email
- a URL
- an IP address
- an HTML tag
- dates
As the list goes down, the regular expressions get more and more elaborate.
The key thing to remember about regular expressions is that they are almost read forwards and backwards at the same time. This sentence will make more sense when we talk about matching HTML tags.
1. Matching a Username
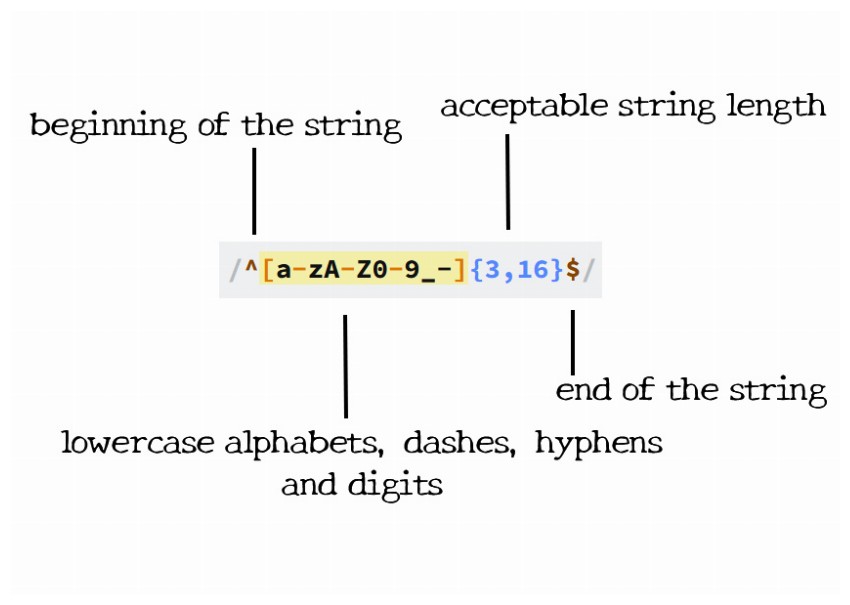
Pattern:
1 |
/^[a-zA-Z0-9_-]{3,16}$/
|
Description:
We begin by telling the parser to find the beginning of the string (^), followed by any lowercase letter (a-z), uppercase letter (A-Z), number (0-9), an underscore, or a hyphen. Next, {3,16} makes sure that are at least 3 of those characters, but no more than 16. Finally, we want the end of the string ($).
String that matches:
my-USER_n4m3
String that doesn't match:
th1s1s-wayt00_l0ngt0beausername (too long)
2. Matching a Password

Pattern:
1 |
/^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?=.*[!@#$^&*()_-]).{8,18}$/
|
Description:
One way to make passwords hard to guess is to make sure that people include at least one digit, at least one small letter, at least one capital letter, and at least one special character. It also makes sense for us to include some kind of length check. For example, the password needs to have a length between 8 and 18 characters.
Our regex checks for all these conditions. The regex is divided into five distinct parts. The first four parts are positive lookahead expressions—in brackets, prefixed by ?=.. The positive lookahead expressions will match anywhere in the string; they don't need to appear in order. Let's consider (?=.*\d) as an example. It looks for any digits anywhere in our string. Similarly, (?=.*[a-z]) looks for any small letters, and (?=.*[A-Z]) looks for capital letters.
Keep in mind that we did not use the expression (?=.*[a-zA-Z]) within our regex. This would have meant that the presence of either a small letter or a capital letter would have given a positive result. We wanted both small and capital letters.
String that matches:
Myp^ssw0rd
String that doesn't match:
Myp^ssword (does not contain any digits)
3. Matching a Hex Value

Pattern:
1 |
/^#?([a-f0-9]{6}|[a-f0-9]{3})$/i
|
Description:
We begin by telling the parser to find the beginning of the string (^). Next, a pound sign is optional because it is followed a ?. The question mark tells the parser that the preceding character—in this case a pound sign —is optional, but to be "greedy" and capture it if it's there.
Next, inside the first group (first group of parentheses), we can have two different situations. The first is any lowercase letter between a and f or a number six times. The | tells us that we can also have three lowercase letters between a and f or numbers instead.
Finally, we want the end of the string ($). We also use the case insensitive flag by adding an i at the end of our expression. This will allow us to match #ffffff as well as #FFFFFF.
The reason that I put the six characters before is that parser will capture a hex value like #ffffff. If I had reversed it so that the three characters came first, the parser would only pick up #fff and not the other three 'f's.
String that matches:
#a3c113
String that doesn't match:
#4d82h4 (contains the letter h)
4. Matching a Slug

Pattern:
1 |
/^[a-z0-9-]+$/ |
Description:
You will be using this regex if you ever have to work with mod_rewrite and pretty URLs. We begin by telling the parser to find the beginning of the string (^), followed by one or more (the plus sign) letters, numbers, or hyphens. Finally, we want the end of the string ($).
String that matches:
my-title-here
String that doesn't match:
my_title_here (contains underscores)
5. Matching an Email
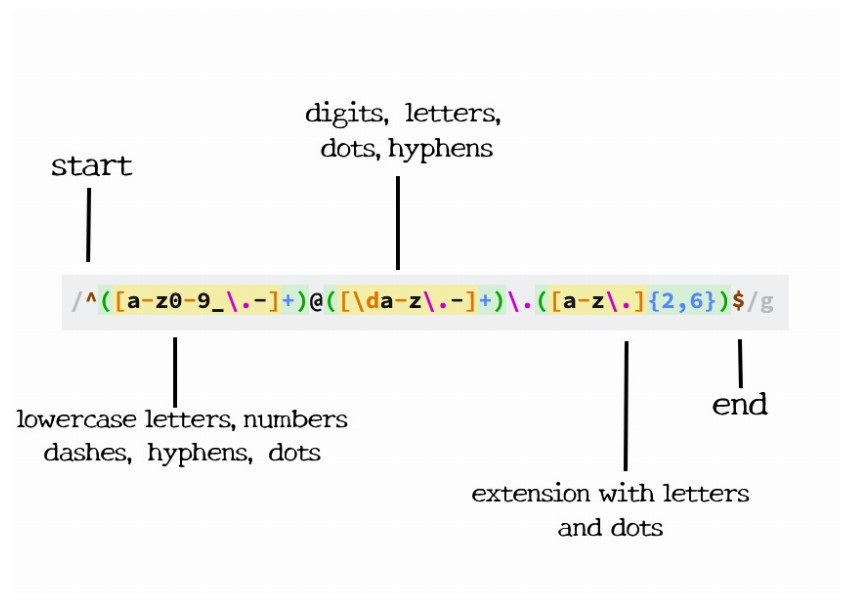
Pattern:
1 |
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,63})$/
|
Description:
We begin by telling the parser to find the beginning of the string (^). Inside the first group, we match one or more lowercase letters, numbers, underscores, dots, or hyphens. I have escaped the dot because a non-escaped dot means any character.
Directly after that, there must be an @ sign. Next is the domain name, which must be one or more lowercase letters, numbers, underscores, dots, or hyphens. Then another (escaped) dot, with the extension being 2 to 63 letters or dots. I have 2 to 63 because of the country-specific TLDs (.ny.us or .co.uk), and of course the new rules allow longer TLDs. Finally, we want the end of the string ($).
String that matches:
john@doe.com
String that doesn't match:
john@doe (TLD is missing)
6. Matching a URL
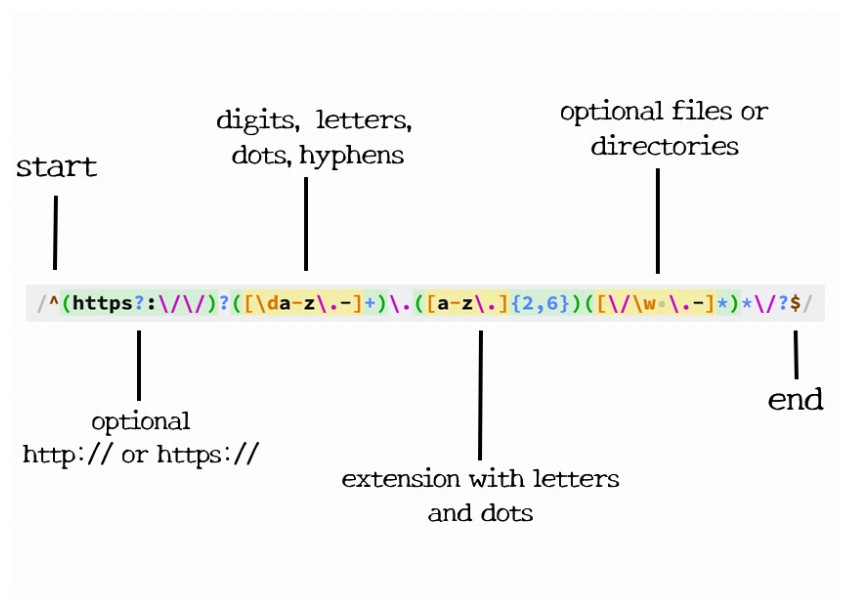
Pattern:
1 |
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
|
Description:
This regex is almost like taking the ending part of the above regex and putting it between "https://" and a file structure at the end. It sounds a lot simpler than it really is. To start off, we search for the beginning of the line with the caret.
The first capturing group is all optional. It allows the URL to begin with "http://", "https://", or neither of them. I have a question mark after the s to allow URLs that have http or https. In order to make this entire group optional, I just added a question mark to the end of it.
Next is the domain name: one or more numbers, letters, dots, or hyphens followed by another dot, then two to six letters or dots.
The following section is for the optional files and directories. Inside the group, we want to match any number of forward slashes, letters, numbers, underscores, spaces, dots, or hyphens. Then we say that this group can be matched as many times as we want. This allows multiple directories to be matched along with a file at the end. I have used the star instead of the question mark because the star says zero or more, not zero or one.
Then a trailing slash is matched, but it can be optional. Finally, we end with the end of the line.
String that matches:
String that doesn't match:
http://google.com/some/file!.html (contains an exclamation point)
7. Matching an IP Address
Pattern:
1 |
/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
|
Description:
Now, I'm not going to lie, I didn't write this regex; I got it from RegExr.
The first capture group really isn't a captured group because ?: was placed inside, which tells the parser not to capture this group (more on this in the last regex). We also want this non-captured group to be repeated three times—the {3} at the end of the group. This group contains another group, a subgroup, and a literal dot. The parser looks for a match in the subgroup and then a dot to move on.
The subgroup is also another non-capture group. It's just a bunch of character sets which together describe the numbers between 0 and 255 (things inside brackets): the string "25" followed by a number between 0 and 5; or the string "2" and a number between 0 and 4 and any number; or an optional zero or one followed by two numbers, with the second being optional.
After we match three of those, it's onto the next non-capturing group. This one wants: the string "25" followed by a number between 0 and 5; or the string "2" with a number between 0 and 4 and another number at the end; or an optional zero or one followed by two numbers, with the second being optional.
We end this confusing regex with the end of the string.
String that matches:
73.60.124.136
String that doesn't match:
256.60.124.136 (all the parts must be less than 255)
8. Matching an HTML Tag
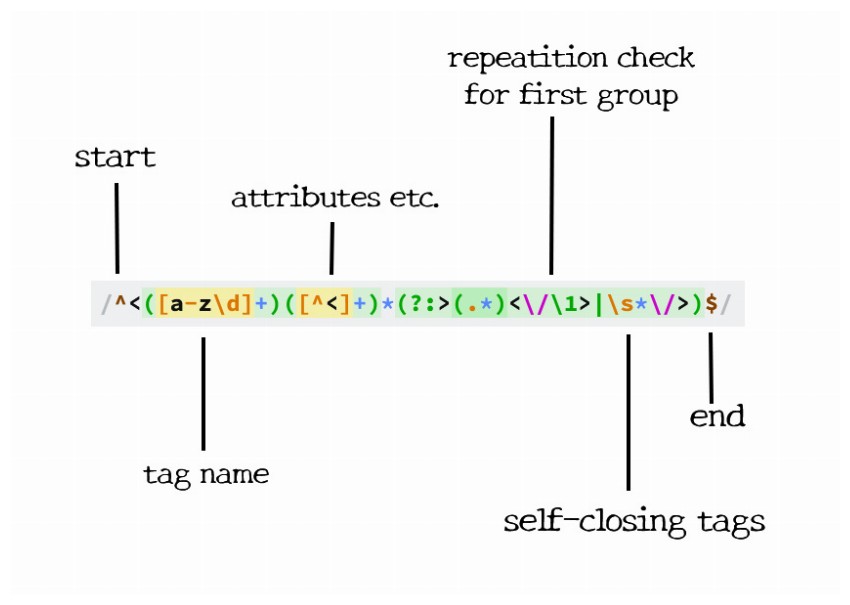
Pattern:
1 |
/^<([a-z\d]+)([^<]+)*(?:>(.*)<\/\1>|\s*\/>)$/ |
Description:
One of the more useful regex expressions on the list. It matches any HTML tag with the content inside. As usual, we begin with the start of the line.
First comes the tag's name. It must be one or more letters long. This is the first capture group, and it comes in handy when we have to grab the closing tag. The next thing is the tag's attributes. This is any character but a greater than sign (>). Since this is optional, but I want to match more than one character, the star is used. The plus sign makes up the attribute and value, and the star says as many attributes as you want.
Next comes the third non-capture group. Inside, it will contain either a greater than sign, some content, and a closing tag; or some spaces, a forward slash, and a greater than sign. The first option looks for a greater than sign followed by any number of characters, and the closing tag. \1 is used which represents the content that was captured in the first capturing group. In this case, it was the tag's name. Now, if that couldn't be matched, we want to look for a self-closing tag (like an img, br, or hr tag). This needs to have one or more spaces followed by "/>".
The regex is ended with the end of the line.
String that matches:
<h1 data-tip="Some Hint">A big Heading</h1>
String that doesn't match:
<h1 data-tip="Some Hint">A big Heading</h2> (the opening and closing tags don't match).
9. Dates
Dates are written in a variety of formats all over the world. For this particular example, we will focus on dates that follow the format DD/MM/YYYY or DD/MM/YY.
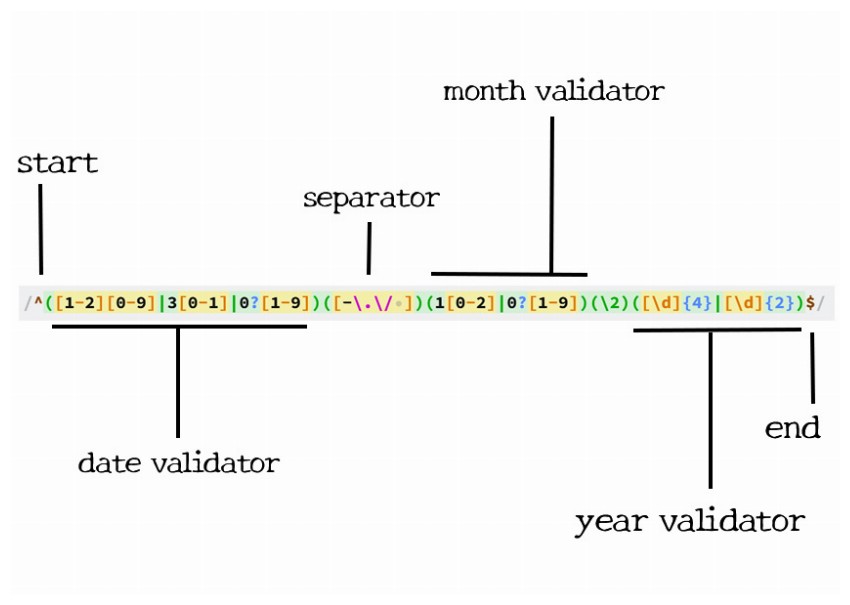
Pattern:
1 |
/^([1-2][0-9]|3[0-1]|0?[1-9])([-\.\/ ])(1[0-2]|0?[1-9])(\2)([\d]{4}|[\d]{2})$/
|
Description:
Let's start with the dates. The dates in a month can go from a minimum value of 1 to 31 at the most. Users can also write the dates as 02 instead of just 2 for the day of the month. We cover all these scenarios with the first part of the expression. As you can see, if the first digit is 1 or 2 we allow the second digit to be anything between 0 and 9. If the first digit is 3, the second digit is only allowed to be 0 or 1.
For separators, we want the characters to only be a hyphen, dot, space, or slash. This is put inside a capturing group so that we can check that the same separator is used between the month and the year value.
The month can only go up to 12, so we allow the second digit to only be 0, 1, or 2 if the first digit is 1. There is no restriction on the year number. It can be any four-digit number like 1508 or 9999. We also allow the year to be written with two digits in case someone wants to write the date as 11/09/91.
Remember that the above regex is for dates which follow the format DD/MM/YYYY. Try modifying it for the date format MM/DD/YYYY.
One more thing that I would like to point out is that the above regex will consider 31.02.1991 as a valid date. However, we know that this is an invalid date since February has at most 29 days. We could write our regex to make sure that the number of days in February never exceeds 28 for regular years and 29 for leap years. However, that would make the regex unnecessarily complicated. It is much more practical to use date validation libraries for these edge cases.
Conclusion
I hope that you have grasped the ideas behind regular expressions a little bit better. Hopefully you'll be using these regexes in future projects! Many times, you won't need to decipher a regex character by character, but sometimes if you do this, it helps you learn. Just remember, don't be afraid of regular expressions—they might not seem it, but they make your life a lot easier. Just try to pull out a tag's name from a string without regular expressions!
This post has been updated with contributions from Monty Shokeen. Monty is a full-stack developer who also loves to write tutorials and to learn about new JavaScript libraries.
 By
By








