

Spanish (Español) translation by David Castrillón (you can also view the original English article)
Las expresiones regulares son un lenguaje en sí mismas. Cuando aprendes un nuevo lenguaje de programación, son este pequeño sub-lenguaje que a primera vista no tiene ningún sentido. Muchas veces tienes que leer otro tutorial, artículo o libro para entender el "simple" patrón descrito. Hoy, repasamos ocho expresiones regulares que debes saber para tu próximo proyecto de código.
Antes de empezar, quizá quieras revisar algunas de las aplicaciones de regex en Envato Market, tales como RegEx Extractor.
Puedes extraer correos electrónicos, números de teléfono de proxies, IPs, direcciones, HTML tags, URL, enlaces, fechas, etcetera. Sólo inserta una o múltiples URL's fuente y expresiones regulares e inicia el proceso.
Extrae, raspa, analiza, cosecha.
Ejemplos de uso
- Extraer correos electrónicos de un viejo libro de direcciones CSV.
- Extraer fuentes de imagen de archivos HTML.
- Extraer proxies de sitios web en línea.
- Extraiga la URL de resultados de Google.
Información de fondo sobre las expresiones regulares
Esto es lo que Wikipedia tiene que decir acerca de ellos:
En computación, las expresiones regulares proporcionan un medio conciso y flexible para identificar cadenas de texto de interés, como caracteres particulares, palabras o patrones de caracteres. Las expresiones regulares (abreviadas como regex o regexp, con formas plurales regexes, regexps o regexen) están escritas en un lenguaje formal que puede ser interpretado por un procesador de expresiones regulares, un programa que bien sirve como un generador o examina el texto e identifica las partes que coinciden con la especificación proporcionada.
Ahora, eso realmente no me dice mucho acerca de los patrones reales. Los regexes sobre los que iré hoy contienen caracteres \w \s, \1, y muchos otros que representan algo totalmente diferente de lo que parecen.
Si deseas aprender un poco sobre las expresiones regulares antes de continuar leyendo este artículo, te sugiero ver las expresiones regularesde la serie de Expresiones Regulares para Dummies.
Las ocho expresiones regulares que revisaremos hoy le permiten emparejar a (n): nombre de usuario, contraseña, correo electrónico, valor hexadecimal (como #fff o #000), slug, URL, IP dirección y una etiqueta HTML. Según como baje la lista, las expresiones regulares se vuelven más y más confusas. Los cuadros para cada regex en principio son fáciles de seguir, pero los últimos cuatro se entienden más fácilmente leyendo la explicación.
Lo importante para recordar acerca de las expresiones regulares es que son casi leidas hacia delante y hacia atrás al mismo tiempo. Esta frase hará más sentido cuando hablamos de etiquetas HTML coincidentes.
Nota: Los delimitadores utilizados en las expresiones regulares son diagonales, "/". Cada patrón comienza y termina con un delimitador. Si una barra diagonal aparece en una expresión regular, las debemos escapar con una barra diagonal inversa: "\ /".
1. Coincidiendoun nombre de usuario

Patrón:
1 |
/^[a-z0-9_-]{3,16}$/
|
2 |
Descripción:
Empezamos diciendole al analizador sintáctico que encuentre el principio de la cadena (^), seguido de cualquier letra minúscula (a-z), número (0-9), un carácter de subrayado o un guión. A continuación, {3,16} asegura que sean al menos 3 de esos caracteres, pero no más de 16. Por último, queremos el final de la cadena ($).
Cadena que coincide:
mi us3r_n4m3
Cadena que no coincide:
th1s1s-wayt00_l0ngt0beausername (demasiado largo)
2. Coincidencia de contraseña

Patrón:
1 |
/^[a-z0-9_-]{6,18}$/
|
2 |
Descripción:
La coincidencia de una contraseña es muy similar a la coincidencia de un nombre de usuario. La única diferencia es que en vez de 3 a 16 letras, números, guiones bajos o guiones, queremos 6 a 18 de ellos ({6,18}).
Cadena que coincide:
myp4ssw0rd
Cadena que no coincide:
Mypa$ $w0rd (contiene un signo de dólar)
3. Coincidencia de un valor hexadecimal

Patrón:
1 |
/^#?([a-f0-9]{6}|[a-f0-9]{3})$/
|
2 |
Descripción:
Empezamos diciendole al analizador sintáctico que encuentre el principio de la cadena (^). A continuación, un signo de número es opcional porque le sigue un signo de interrogación. El signo de interrogación indica al analizador sintáctico que el carácter precedente — en este caso un signo de número, es opcional, pero lo necesario para ser "codicioso" y capturarlo si está allí. Luego, dentro del primer grupo (primer grupo de paréntesis), podemos tener dos situaciones diferentes. El primero es cualquier letra minúscula entre a y f o un número seis veces. La barra vertical nos dice que también podemos tener tres letras minúsculas entre a y f o números en su lugar. Por último, queremos el final de la cadena ($).
La razón por la que pongo seis caracteres antes es que el analizador capturará un valor hexadecimal como #ffffff. Si lo invirtiera para que los tres caracteres vengan primeros, el analizador sólo recogería #fff y no los otros tres f.
Cadena que coincide:
#a3c113
Cadena que no coincide:
#4d82h4 (contiene la letra h)
4. Coincidencia de un Slug

Patrón:
1 |
/^[a-z0-9-]+$/ |
2 |
Descripción:
Vas a utilizar esta expresión regular si alguna vez tienes que trabajar con mod_rewrite y pretty URL. Comenzamos diciendole al analizador sintáctico que encuentre el principio de la cadena (^), seguido por uno o más (el signo) letras, números o guiones. Por último, queremos el final de la cadena ($).
Cadena que coincide:
my-title-here
Cadena que no coincide:
my_title_here (contiene subrayados)
5. Coincidencia de un correo electrónico
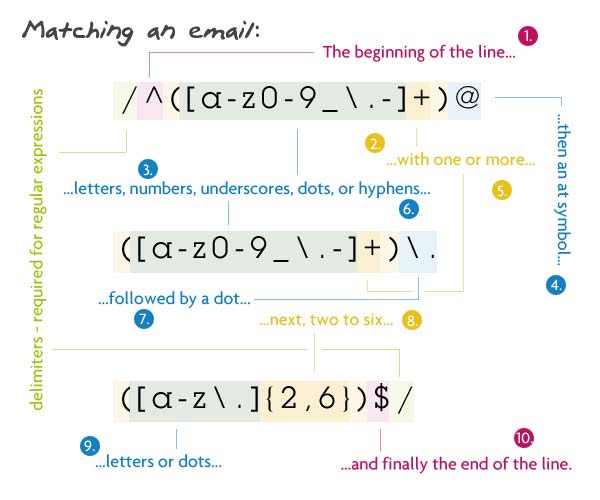
Patrón:
1 |
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/
|
2 |
Descripción:
Empezamos diciendole al analizador sintáctico que encuentre el principio de la cadena (^). Dentro del primer grupo, coincidimos con una o más letras minúsculas, números, subrayados, puntos o guiones. He escapado el punto porque un punto no escapado significa cualquier carácter. Directamente después de eso, debe haber una arroba. El siguiente es el nombre del dominio que debe ser: una o más letras minúsculas, números, subrayados, puntos o guiones. Luego otro punto (escapado), con la extensión de dos a seis letras o puntos. Tengo 2 a 6 por la especificación del país TLD (. ny.us o. co.uk). Por último, queremos finalizar la cadena ($).
Cadena que coincide:
john@doe.com
Cadena que no coincide:
john@doe.algo (el TLD es demasiado largo)
6. Coincidencia de una dirección URL

Patrón:
1 |
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
|
2 |
Descripción:
Esta expresión regular es casi como tomar la parte final del anterior regex, y acomodarlo entre "http://" y alguna estructura de archivo al final. Suena mucho más sencillo de lo que realmente es. Para empezar, buscamos el principio de la línea con el símbolo de intercalación.
El primer grupo capturado es opcional. Permite que la URL comience con "http://", "https://" o ninguno de ellos. Tengo un signo de interrogación después de la s para permitir que las URL´s tengan http o https. Para hacer este grupo entero opcional, acabo de añadir un signo de interrogación al final de la misma.
El siguiente es el nombre de dominio: uno o más números, letras, puntos o guiones seguido de otro punto y luego de dos a seis letras o puntos. La siguiente sección son los directorios y archivos opcionales. Dentro del grupo, queremos coincidir con cualquier número de diagonales, letras, números, caracteres de subrayado, espacios, puntos o guiones. Entonces decimos que este grupo puede combinarse tantas veces como queramos. Más o menos esto permite que múltiples directorios se combinen junto con un archivo al final. He utilizado la estrella en lugar del signo de interrogación porque la estrella dice cero o más, no cero o uno. Si un signo de interrogación iba a utilizarse allí, sólo un archivo/directorio podrían combinarse.
Una barra coincide, pero puede ser opcional. Finalmente terminamos con el final de la línea.
Cadena que coincide:
https://net.tutsplus.com/about
Cadena que no coincide:
http://Google.com/some/File!.html (contiene un signo de exclamación)
7. Coincidencia de una dirección IP

Patrón:
1 |
/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
|
2 |
Descripción:
Ahora, no voy a mentir, yo no escribí esta regex; la saqué de aqui. Ahora, eso no significa que no puedo desmenuzarla carácter por carácter.
El primer grupo de captura realmente no es un grupo capturado, ya
1 |
?: |
2 |
que se colocó dentro de la cual le dice al analizador no captar a este grupo (más sobre esto en el pasado regex). También queremos que este grupo que no capturó se repita tres veces — {3} al final del grupo. Este grupo contiene otro grupo, un subgrupo y un punto literal. El analizador busca una coincidencia en el subgrupo luego un punto para pasarlo.
El subgrupo es también otro grupo sin captura. Es sólo un montón de juegos de caracteres (cosas dentro de corchetes): la cadena "25" seguido de un número entre 0 y 5; o la cadena "2" y un número entre 0 y 4 y de cualquier número; o un cero opcional o uno seguido de dos números, el segundo es opcional.
Después de que coincidimos con tres de aquellos, es en el siguiente grupo de no-captura. Este quiere: la cadena "25" seguida de un número entre 0 y 5; o la cadena "2" con un número entre 0 y 4 y otra al final; o un cero opcional o uno seguido de dos números, el segundo es opcional.
Terminamos este regex confuso con el final de la cadena.
Cadena que coincide:
73.60.124.136 (no, esa no es mi dirección IP :P)
Cadena que no coincide:
256.60.124.136 (el primer grupo debe ser "25" y un número entre cero y cinco)
8. Coincidencia de una etiqueta HTML

Patrón:
1 |
/^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$/ |
2 |
Descripción:
Uno de los regexes más útil en la lista. Coincide con cualquier etiqueta HTML en el contenido. Como de costumbre, comenzamos con el inicio de la línea.
Primero viene el nombre de la etiqueta. Debe ser una o más letras de largo. Este es el primer grupo de captura, viene bien cuando tenemos que tomar la etiqueta de cierre. Lo siguiente son los atributos de la etiqueta. Este es cualquier caracter pero es el signo mayor que(>). Ya que esto es opcional, pero como yo quiero más de un carácter, se utiliza la estrella. El signo más constituye el atributo y el valor, y la estrella dice tantos atributos como desees.
Luego viene el tercer grupo sin captura. En su interior, contendrá un signo mayor que, algo de contenido y una etiqueta de cierre; o algunos espacios, una barra y un signo mayor que. La primera opción busca un signo mayor que seguido por cualquier número de caracteres y la etiqueta de cierre. \1 se utiliza el cual representa el contenido que fue capturado en el primer grupo de captura. En este caso fue el nombre de la etiqueta. Ahora, si no pudiera ser igualada queremos buscar una etiqueta de autocierre (como una etiqueta img, br o hr). Esto debe tener uno o más espacios, seguidos de "/ >".
El regex es terminado con el final de la línea.
Cadena que coincide:
Nettuts "> http://net.tutsplus.com/" > Nettuts +
Cadena que no coincide:
< img src="img.jpg" alt = "mi imagen >" / > (los atributos no pueden contener signos de mayor que)
Conclusión
Espero que hayas captado la idea detrás de las expresiones regulares un poco mejor. ¡Esperemos que utilices estos regexes en futuros proyectos! Muchas veces no tendrás que descifrar un regex carácter por carácter, pero a veces si haces esto te ayuda a aprender. Sólo recuerda, no tengas miedo de las expresiones regulares, puede que no lo parezca, pero hacen tu vida mucho más fácil. Sólo prueba y saca el nombre de una etiqueta de una cadena sin expresiones regulares!
Síguenos en Twitter, o Suscríbete a los RSS Feed de NETTUTS para más tutoriales y artículos diarios de desarrollo web. Y revisa algunas de las aplicaciones de regex en Envato Market
 By
By









