


Trees are one of the most commonly used data structures in web development. This statement holds true for both developers and users. Every web developer who has written HTML and loaded it into a web browser has created a tree, which is referred to as the Document Object Model (DOM). Every user of the Internet who has, in turn, consumed information on the Internet has received it in the form of a tree—the DOM.
That's right, the article that you are reading at this moment is rendered in your browser as a tree! The paragraph that you are reading is represented as text in a <p> element; the <p> element is nested inside a <body> element; and the <body> element is nested inside an <html> element.
.png)
The nesting of data is similar to a family tree. The <html> element is a parent, the <body> element is a child, and the <p> element is a child of the <body> element. If this analogy of a tree seems useful to you, then you will find comfort in knowing that more analogies will be used during our implementation of a tree.
In this article, we will create a tree using two different methods of tree traversal: depth-first search (DFS) and breadth-first search (BFS). (If the word traversal is unfamiliar to you, consider it to mean visiting every node of the tree.) Both of these types of traversals highlight different ways of interacting with a tree; both travels, moreover, incorporate the use of data structures that we've covered in this series. DFS uses a stack and BFS uses a queue to visit nodes. That's cool!
Traversing a Tree With Depth-First Search and Breadth-First Search
In computer science, a tree is a data structure that simulates hierarchical data with nodes. Each node of a tree holds its own data and pointers to other nodes.
The terminology of nodes and pointers may be new to some readers, so let's describe them further with an analogy. Let's compare a tree to an organizational chart. The chart has a top-level position (root node), such as CEO. Directly underneath this position are other positions, such as vice president (VP).
@1.25x.png)
To represent this relationship, we use arrows that point from the CEO to a VP. A position, such as the CEO, is a node; the relationship we create from a CEO to a VP is a pointer. To create more relationships in our organizational chart, we just repeat this process—we have a node point to another node.
On a conceptual level, I hope that nodes and pointers make sense. On a practical level, we can benefit from using a more technical example. Let's consider the DOM. A DOM has an <html> element as its top-level position (root node). This node points to a <head> element and a <body> element. This structure is repeated for all nodes in the DOM.
One of the beauties of this design is the ability to nest nodes: a <ul> element, for instance, can have many <li> elements nested inside it; moreover, each <li> element can have sibling <li> nodes.
Depth-First Search (DFS)
The depth-first search or DFS starts at the initial node and goes deeper into the tree until the desired element or an element with no children—a leaf—is found. And then, it backtracks from the leaf node and visits the most recent node that is not yet explored.
.png)
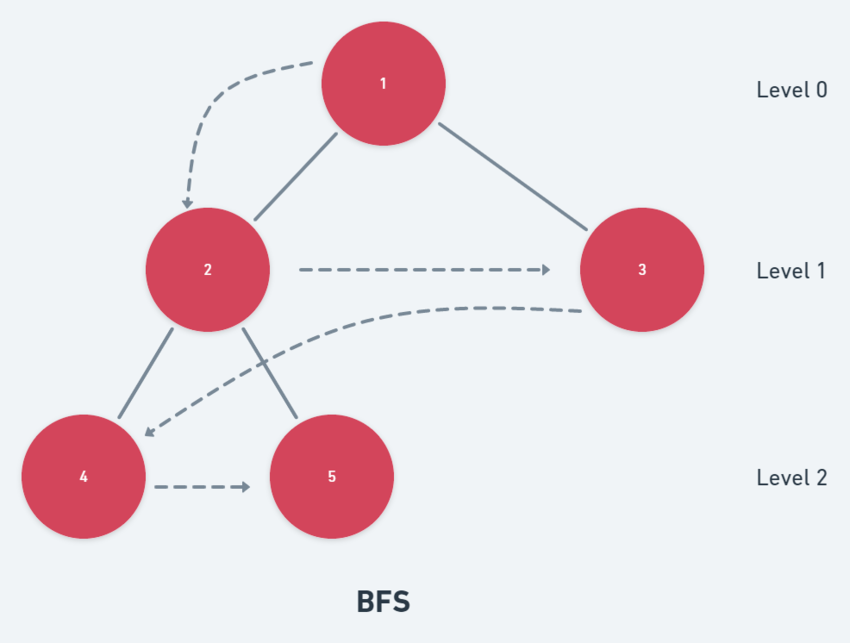
Breadth-First Search (BFS)
In a breadth-first search, the tree traversal starts from the root node and first traverses all the neighboring nodes. Then, it selects the nearest node and explores the new nodes. This method is repeated for each node until it reaches the destination.
Operations of a Tree
Since every tree contains nodes, which can be a separate constructor from a tree, we will outline the operations of both constructors: Node and Tree.
Node
-
datastores a value -
parentpoints to a node's parent -
childrenpoints to the next node in the list
Tree
-
_rootpoints to the root node of a tree -
find(data): return the node containing the given data -
add(data, parentData): add a new node to the parent containing the given data -
remove(data): remove the node containing the given data -
forEach(callback): run a callback on each node of the tree in depth-first order -
forEachBreathFirst(callback): run a callback on each node of the tree in breadth-first order
Implementing a Tree in JavaScript
Now let's write the code for a tree!
The Node Class
For our implementation, we will first define a class named Node and then a constructor named Tree.
1 |
class Node { |
2 |
constructor(data) { |
3 |
this.data = data; |
4 |
this.parent = null; |
5 |
this.children = []; |
6 |
}
|
7 |
}
|
Every instance of Node contains three properties: data, parent, and children. The first property holds data associated with a node—the payload of the tree. parent points to the single node that this node is the child of. children points to all the child nodes of this node.
The Tree Class
Now, let's define our constructor for Tree, which includes the Node constructor in its definition:
1 |
class Tree { |
2 |
constructor(data) { |
3 |
let node = new Node(data); |
4 |
this._root = node; |
5 |
}
|
6 |
|
7 |
//other Tree methods...
|
8 |
}
|
Tree contains two lines of code. The first line creates a new instance of Node; the second line assigns node as the root of a tree.
The definitions of Tree and Node require only a few lines of code. These lines, however, are enough to help us simulate hierarchical data. To prove this point, let's use some example data to create an instance of Tree (and, indirectly, Node).
1 |
let tree = new Tree('CEO'); |
2 |
|
3 |
// {data: 'CEO', parent: null, children: []}
|
4 |
tree._root; |
Thanks to the existence of parent and children, we can add nodes as children of _root and also assign _root as the parents of those nodes. In other words, we can simulate the creation of hierarchical data.
Methods of Tree
Next, we will create the following five methods:
-
find(data): return the node containing the given data -
add(data, parentData): add a new node to the parent containing the given data -
remove(data): remove the node containing the given data -
forEach(callback): run a callback on each node of the tree in depth-first order -
forEachBreathFirst(callback): run a callback on each node of the tree in breadth-first order
Since the add and remove methods require us to find a specific node, we'll start with that method, using a depth-first search.
Depth-First Search With find(data)
This method traverses a tree with depth-first search.
1 |
//returns the node that has the given data, or null
|
2 |
//use a depth-first search
|
3 |
find(data, node = this._root) { |
4 |
//if the current node matches the data, return it
|
5 |
if (node.data == data) |
6 |
return node; |
7 |
|
8 |
//recurse on each child node
|
9 |
for (let child of node.children) { |
10 |
//if the data is found in any child node it will be returned here
|
11 |
if (this.find(data, child)) |
12 |
return child; |
13 |
}
|
14 |
|
15 |
//otherwise, the data was not found
|
16 |
return null; |
17 |
}
|
find() is a recursive function with a parameter for the data to find and for the node to search under. find also has a parameter for the current node—this starts out as the tree root, and is later used to recurse over the child nodes.
The for iterates over each child of node, beginning with the first child. Inside the body of the for loop, we invoke the find() function recursively with that child. When the data is found, it will be returned back through the whole stack of function calls, terminating the search.
If no matching node is found, null will be eventually returned.
Note that this is a depth-first search—find will recursively drill down to the leaf nodes of the tree and work its way back up.
Understanding Recursion
Recursion is a very hard topic to teach and requires an entire article to adequately explain it. Since the explanation of recursion isn't the focus of this article—the focus is implementing a tree—I'll suggest that any readers lacking a good grasp of recursion experiment with our implementation of find() and try to understand how it works.
I'll include a live example below so you can try it out.
Adding Elements to the Tree
Here's the implementation of our add method:
1 |
//create a new node with the given data and add it to the specified parent node
|
2 |
add(data, parentData) { |
3 |
let node = new Node(data); |
4 |
let parent = this.find(parentData); |
5 |
|
6 |
//if the parent exists, add this node
|
7 |
if (parent) { |
8 |
parent.children.push(node); |
9 |
node.parent = parent; |
10 |
|
11 |
//return this node
|
12 |
return node; |
13 |
}
|
14 |
//otherwise throw an error
|
15 |
else { |
16 |
throw new Error(`Cannot add node: parent with data ${parentData} not found.`); |
17 |
}
|
18 |
}
|
The add method lets us specify the data for the new node, and also the parent node we want to add it to.
First we search for the parent node with the given data. If it's found, we'll add the new node to the parent's list of children. We'll also link the parent to the new node. Now the new node is linked into its place in the tree.
Removing Elements From the Tree
Here's how we'll implement our remove method:
1 |
//removes the node with the specified data from the tree
|
2 |
remove(data) { |
3 |
//find the node
|
4 |
let node = this.find(data) |
5 |
|
6 |
//if the node exists, remove it from its parent
|
7 |
if (node) { |
8 |
//find the index of this node in its parent
|
9 |
let parent = node.parent; |
10 |
let indexOfNode = parent.children.indexOf(node); |
11 |
//and delete it from the parent
|
12 |
parent.children.splice(indexOfNode, 1); |
13 |
}
|
14 |
//otherwise throw an error
|
15 |
else { |
16 |
throw new Error(`Cannot remove node: node with data ${data} not found.`); |
17 |
}
|
18 |
}
|
Just like for the add method, first we search for the node with the given data. When we find it, we can delete that node and all of its children from the tree by removing it from its parent. Here we use indexOf() to find the node in the parent's list of children, then we use splice() to delete it from that list.
Depth-First Tree Traversal With forEach()
Next we'll add a forEach() method to our tree so that we can traverse it and apply a custom callback to each node.
1 |
//depth-first tree traversal
|
2 |
//starts at the root
|
3 |
forEach(callback, node = this._root) { |
4 |
//recurse on each child node
|
5 |
for (let child of node.children) { |
6 |
//if the data is found in any child node it will be returned here
|
7 |
this.forEach(callback, child); |
8 |
}
|
9 |
|
10 |
//otherwise, the data was not found
|
11 |
callback(node); |
12 |
}
|
Just like the find() method, this is a depth-first traversal. This will visit each node in the tree, starting at the bottom of the first branch and working its way through the whole tree. Imagine an ant crawling from one leaf, up the branch and then back down to another leaf, and so on.
We can test the traversal out with by creating a new tree as below.
1 |
let t = new Tree("CEO"); |
2 |
t.add("VP Finance", "CEO"); |
3 |
t.add("VP Sales", "CEO"); |
4 |
t.add("Salesperson", "VP Sales"); |
5 |
t.add("Accountant", "VP Finance"); |
6 |
t.add("Bookkeeper", "VP Finance"); |
7 |
|
8 |
t.forEach(node => console.log(node.data)); |
in the forEach() call, we created a simple callback that logs each node to the console as it is visited. If we run this code, we'll get the following output.
1 |
Accountant |
2 |
Bookkeeper |
3 |
VP Finance |
4 |
Salesperson |
5 |
VP Sales |
6 |
CEO |
Breadth-First Traversal With forEachBreadthFirst()
For most uses, a depth-first search is simpler and just as effective, but sometimes a breadth-first traversal is called for. Here's our final method of the Tree class.
1 |
//breadth-first tree traversal
|
2 |
forEachBreadthFirst(callback) { |
3 |
//start with the root node
|
4 |
let queue = []; |
5 |
queue.push(this._root); |
6 |
|
7 |
//while the queue is not empty
|
8 |
while (queue.length > 0) { |
9 |
//take the next node from the queue
|
10 |
let node = queue.shift(); |
11 |
|
12 |
//visit it
|
13 |
callback(node); |
14 |
|
15 |
//and enqueue its children
|
16 |
for (let child of node.children) { |
17 |
queue.push(child); |
18 |
}
|
19 |
}
|
20 |
}
|
Where a depth-first traversal uses recursion to search the tree, the breadth-first traversal uses a queue structure. As each node is visited, its children are pushed on to the back of the queue. The next nodes to visit are taken from the front of the queue, which ensures that higher-level nodes are visited before their child nodes.
Using the same tree as above, if we traverse the tree with forEachBreadthFirst(), we'll visit the nodes in a different order. Here's the code:
1 |
t.forEachBreadthFirst(node => console.log(node.data)); |
And here's the traversal it produces:
1 |
CEO |
2 |
VP Finance |
3 |
VP Sales |
4 |
Accountant |
5 |
Bookkeeper |
6 |
Salesperson |
As you can see, this time the nodes are traversed from the top to the bottom.
Interactive Example of a JavaScript Tree Structure
Here is an interactive example with all the code from this post. You can experiment with creating different trees and modifying or traversing them.
Conclusion
Trees simulate hierarchical data. Much of the world around us resembles this type of hierarchy, such as web pages and our families. Any time you find yourself in need of structuring data with hierarchy, consider using a tree!
This post has been updated with contributions from Subha Chanda. A freelance web developer and a technical writer, Subha has a passion for learning and sharing experiences with others.
 By
By









