
Whether you lean to the right or the left, there's little doubt that, if you're a Nettuts+ reader, you'll likely agree that technology is rapidly shaping politics. In United States Presidential campaigns, the web was a major platform for front-facing unification of a message, but it was also a core part of each side's internal processes.
Recently, we had the opportunity to interview Daniel Ryan - the Director of Frontend Development for "Obama for America" - about the strategies, technologies, and experiences that were a part of the race to November 6.
QWhat was the biggest large-scale challenge for the design and development teams during the campaign?
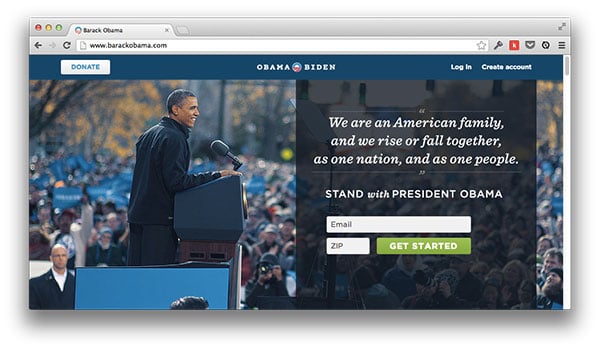
The biggest scale challenge wasn't a single project; it was the sheer volume of requests we got each day. Our dev team was split among three areas: fundraising, persuasion and getting voters to the polls. Turning around new designs through approvals by messaging, policy, research, legal, etc., then launching those projects within a few days or often a few hours was the single largest challenge. Both Design and Dev had a team of Producers who managed those requests, assigned them to relevant staff and saw them through completion.
The biggest challenge [...] was the shear volume of requests we got each day.
Q How did the campaign approach A/B testing and data-driven design decision-making?
One of the things that has been said often about the campaign is that we were data driven. This couldn't be more true. My deputy Kyle Rush oversaw an optimization working group consisting of developers, designers, user experience engineers, data analysts, online ad specialists and content writers. We used a mix of approaches, mostly focused on Optimizely for A/B testing to prove (and disprove, often) theses about how pages could perform better.
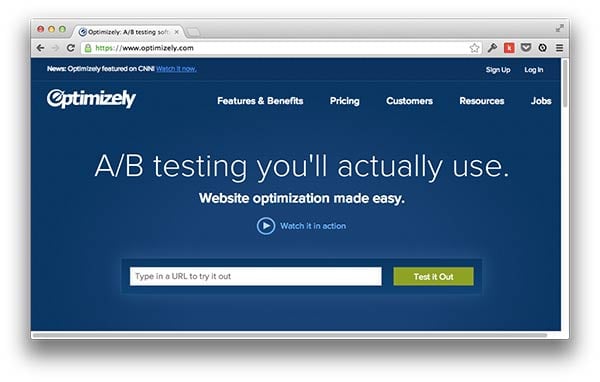
Our traffic levels meant we could run multiple tests per day to significant levels. A weekly report was compiled with updated best practices and recommendations based on those findings. We estimate that we achieved about $125 million in incremental improvements to our fundraising pages alone.
Q Can you give us a simple run-down of the stack, from back to front?
There wasn't a single stack. One of the smartest things we did was run dozens of decoupled systems tied together with JavaScript and Akamai services. Broadly, our stack ran on Amazon Web Services, including thousands of EC2 instances, several large database clusters and S3 hosting. Our main site, www.barackobama.com, was an Expression Engine install backed by EC2 and RDS and fronted by Akamai caching.
Akamai offloaded about 98% of all of our traffic. Additionally we used Jekyll, multiple custom apps built on Django, Flask, Rails and Magento. Our widest-used language was Python.
One of the smartest things we did was run dozens of decoupled systems tied together with JavaScript and Akamai services.
Q What are some of the open-source tools OFA used during the campaign? What was the production/deployment strategy?
On the client-side, we rolled our own CSS grid and core styles along with jQuery, Modernizr and a core JavaScript library that lazy loaded modules as needed. We used Mustache.js templates quite a bit for browser-based apps. As the first responsive website for a national campaign, we tried out a lot of open source tools for making mobile experiences better. Fitvids.js was one of the heaviest used. Internally, we worked in LESS CSS, compiled by CodeKit. One of the devs showed me LESS while we were overhauling the site in October 2011; by the end of the day, the whole site had switched to it. This is just one example of how we stayed open to better approaches every day and weren't scared to embrace a new method or system if it made sense.
We ran git as our VCS of choice, for all the obvious reasons. All of our code went through Github, which also served as our main code management flow. We were heavily guided by the principles of "How Github Uses Github to Build Github". Wherever it made sense, our flow was:
- branch locally
- set a Git tag on the repo once the code was ready for review and testing
- deploy the tag to staging servers
- code review and QA
- once the code was production ready, set up a pull request to the master branch
- pull requests were reviewed by lead developers or senior developers; static assets were deployed to S3, while server-side code required a deploy request to our DevOps team
- the DevOps team used Puppet and Gippetto to create apk distros for the Linux boxes
- small code changes would get deployed on the fly; large ones would get built out under new server clusters, tested internally and then swapped in place of the old version
We didn't get to use this flow everywhere we would have liked, because we came into a working system, rather than starting from scratch. When I arrived in August 2011, there were no dev or staging environments for our main site, for instance. We got a staging system in place pretty quickly, but always struggled to have local dev environments for Expression Engine.
Q Where did design ideas originate? What was the process of taking an idea from birth to deployment?
Design ideas largely came from the Design team directly. Josh Higgins, our Design Director, and I worked very hard to make sure our teams collaborated continuously. We sat in our own section of the office, along with the program/project managers, so we could keep the two teams working physically near each other. Many of the designs we rolled out started by a designer or developer finding a cool idea somewhere and emailing it around to the two teams. These ideas then became the vernacular we would talk in when trying to come up with a specific concept. As with everything else, though, data was our guide. No matter how cool we thought something was, if the data showed it wasn't getting the results we wanted, we would try another approach.
Many of the designs we rolled out started by a designer or developer finding a cool idea somewhere and emailing it around to the two teams. These ideas then became the vernacular we would talk in when trying to come up with a specific concept.
The process was much like any good digital agency. We'd have a kickoff meeting with PMs, Producers, Leads, etc. to figure out the scope of a project. Someone would send around the notes from that, and we'd all tweak them for a bit then send up to our leadership to get sign off on the direction we wanted to go in. After incorporating feedback, either a designer would begin comps or, for more complicated projects, a developer would begin prototypes. The assigned developer and designer would iterate through those until the project was live and ready for testing. Normally, we would send the staging version around for approvals at the same time the QA team was doing cross-browser testing. The team would iterate on the notes from both and then we'd launch. Keep in mind that near the end of the summer, we were doing this on a dozen projects or more simultaneously. Many times, we'd do this whole cycle in a single day.
Q We have read a bit about the technical issues that plagued the Romney camp throughout the campaign, including server outages and hard drive failures. What were some of the most important strategic decisions the Obama team made to avoid these problems?
I think our approach basically boiled down to pragmatic paranoia.
This was my first campaign as a staffer, but we had many alumni from '08 with us. I think I had been in Chicago less than a week before I'd heard about the failure of Houdini, which was the Obama '08 system akin to Romney's Orca. Because of the institutional experience with this voter monitoring system's failure, we never put ourselves in a place where a single system failure could do real damage. We had the luxury of time, which we used in part to build redundancies. Our payment processor, for instance, was actually one in-house system and one vendor system that Akamai flipped between automatically if one side went down. That system worked so well we replicated it for polling places. We had two APIs, one internal and one powered by Google, with a thin PHP app to make the output the same. Not only could Akamai automatically fail between them without the end user noticing, but we had a system in place where we could choose which states used which system proactively. This let us prevent a traffic spike outage. The systems we relied upon specifically for Election Day all had two backup systems: one powered by Google Doc spreadsheets and one consisting of printed hard-copies of critical data. I think our approach basically boiled down to pragmatic paranoia.
Q How did responsive design play a role in the Obama strategic team? Was the design "mobile first"?


Early on, the campaign tried making a jQuery Mobile powered site, but maintaining two templates for everything simply wasn't going to scale. We were seeing 25% of our traffic come from mobile devices, but almost none of our donations. When we set out to do a site overhaul in Fall 2011, it was a foregone conclusion we would do mobile-first, responsive/adaptive. It was a learning process for all of us. If there's one takeaway I would really stress, mobile-first doesn't mean starting with a 320 pixel wide design, it means starting with a low bandwidth experience. We learned that lesson over and over throughout the course of the campaign. Mobile first is a comprehensive approach including content creation that is mobile friendly, design that is flexible and code that is as lean as possible.
Mobile-first doesn't mean starting with a 320 pixel wide design, it means starting with a low bandwidth experience.
Q What was the biggest lesson to be learned about large-scale deployment?
The biggest lesson I learned about large-scale deployment is hire smart people. When you're trying to tune for scale, especially in the hockey stick curve we knew we were going to have, you need people at every part of the stack thinking about how to be more efficient. Most of my team had no experience at the kind of scale we wound up working at, but we learned quickly and adapted.
Q What was the general management structure of projects for the Obama team?
I truly believe that this is the last presidential campaign where the "Internet people" will be separated into their own group.
The structure varied by project, but our overall structure was basically divided into those three buckets I mentioned before: fundraising, persuasion and turning out voters. Internally, there was a Digital Department, which my team was part of along with Design, Online Ads, Social, Email, Content, Digital Analytics, Program Managers, Video, Online Organizing, Rapid Response and our management team. Generally speaking, we handled all the public-facing work of the campaign online. Additionally, the Tech Department was responsible for the infrastructure (our DevOps team) and the server-side code for virtually everything we did. There was some crossover between the two departments as well. A large part of my role was coordinating with Tech and DevOps as we constantly deployed more and more systems.
I truly believe that this is the last presidential campaign where the "Internet people" will be separated into their own group. Our work covered every area of the campaign at some point. 2016 should be much more of a matrix org chart than a hierarchical one.
In Closing
Thanks again to Daniel for agreeing to speak with us. To stay up to date, be sure to follow him on Twitter, and keep an eye on his website.

 By
By










