
JavaScript is over fifteen years old; nevertheless, the language is still misunderstood by what is perhaps the majority of developers and designers using the language. One of the most powerful, yet misunderstood, aspects of JavaScript are functions. While terribly vital to JavaScript, their misuse can introduce inefficiency and hinder an application's performance.
Prefer a Video Tutorial?
Performance is Important
In the Web's infancy, performance wasn't very important.
In the Web's infancy, performance wasn't very important. From the 56K (or worse) dial-up connections to an end-user's 133MHz Pentium computer with 8MB of RAM, the Web was expected to be slow (although that didn't stop everyone from complaining about it). It was for this reason JavaScript was created to begin with, to offload simple processing, such as form validation, to the browser—making certain tasks easier and quicker for the end-user. Instead of filling out a form, clicking submit, and waiting at least thirty seconds to be told you entered incorrect data in a field, JavaScript enabled Web authors to validate your input and alert you to any errors prior to the form's submission.
Fast forward to today. End users enjoy multi-core & multi-GHz computers, an abundance of RAM, and fast connection speeds. JavaScript is no longer relegated to menial form validation, but it can process large amounts of data, change any part of a page on the fly, send and receive data from the server, and add interactivity to an otherwise static page—all in the name of enhancing the user's experience. It's a pattern quite well known throughout the computer industry: a growing amount of system resources enable developers to write more sophisticated and resource dependent operating systems and software. But even with this abundant and ever growing amount of resources, developers must be mindful of the amount of resources their app consumes—especially on the web.
Today's JavaScript engines are light-years ahead of the engines of ten years ago, but they do not optimize everything. What they don't optimize is left to developers.
There is also a whole new set of web-enabled devices, smart phones and tablets, running on a limited set of resources. Their trimmed down operating systems and apps are certainly a hit, but the major mobile OS vendors (and even desktop OS vendors) are looking towards Web technologies as their developer platform of choice, pushing JavaScript developers to ensure their code is efficient and performant.
A poor performing application will trash a good experience.
Most importantly, the user's experience depends on good performance. Pretty and natural UIs certainly add to a user's experience, but a poor performing application will trash a good experience. If users do not want to use your software, then what is the point of writing it? So, it is absolutely vital that, in this day and age of Web-centric development, JavaScript developers write the best code possible.
So what does all this have to do with functions?
Where you define your functions has an impact on your application's performance.
There are many JavaScript anti-patterns, but one involving functions has become somewhat popular—especially in the crowd that strives to coerce JavaScript to emulate features in other languages (features like privacy). It is nesting functions in other functions, and if done incorrectly, it can have an adverse affect on your application.
It's important to note that this anti-pattern does not apply to all instances of nested functions, but it is typically defined by two characteristics. First, the creation of the function in question is usually deferred—meaning that the nested function is not created by the JavaScript engine at load-time. That in and of itself isn't a bad thing, but it's the second characteristic that hinders performance: the nested function is repeatedly created due to repeated calls to the outer function. So while it may be easy to say "all nested functions are bad," that is certainly not the case, and you will be able to identify problematic nested functions and fix them to speed up your application.
Nesting Functions in Normal Functions
The first example of this anti-pattern is nesting a function inside a normal function. Here is an oversimplified example:
1 |
function foo(a, b) { |
2 |
function bar() { |
3 |
return a + b; |
4 |
}
|
5 |
|
6 |
return bar(); |
7 |
}
|
8 |
|
9 |
foo(1, 2); |
You may not write this exact code, but it's important to recognize the pattern. An outer function, foo(), contains an inner function, bar(), and calls that inner function to do work. Many developers forget that functions are values in JavaScript. When you declare a function in your code, the JavaScript engine creates a corresponding function object—a value that can be assigned to a variable or passed to another function. The act of creating a function object resembles that of any other type of value; the JavaScript engine doesn't create it until it needs to. So in the case of the above code, the JavaScript engine doesn't create the inner bar() function until foo() executes. When foo() exits, the bar() function object is destroyed.
The fact that foo() has a name implies it will be called multiple times throughout the application. While one execution of foo() would be considered OK, subsequent calls cause unnecessary work for the JavaScript engine because it has to recreate a bar() function object for every foo() execution. So, if you call foo() 100 times in an application, the JavaScript engine has to create and destroy 100 bar() function objects. Big deal, right? The engine has to create other local variables within a function every time it's called, so why care about functions?
Unlike other types of values, functions typically don't change; a function is created to perform a specific task. So it doesn’t make much sense to waste CPU cycles recreating a somewhat static value over and over again.
Ideally, the bar() function object in this example should only be created once, and that's easy to achieve—although naturally, more complex functions may require extensive refactoring. The idea is to move the bar() declaration outside of foo() so that the function object is only created once, like this:
1 |
function foo(a, b) { |
2 |
return bar(a, b); |
3 |
}
|
4 |
|
5 |
function bar(a, b) { |
6 |
return a + b; |
7 |
}
|
8 |
|
9 |
foo(1, 2); |
Notice that the new bar() function isn't exactly as it was inside of foo(). Because the old bar() function used the a and b parameters in foo(), the new version needed refactoring to accept those arguments in order to do its work.
Depending upon the browser, this optimized code is anywhere from 10% to 99% faster than the nested version. You can view and run the test for yourself at jsperf.com/nested-named-functions. Do keep in mind the simplicity of this example. A 10% (at the lowest end of the performance spectrum) performance gain doesn't seem like a lot, but it would be higher as more nested and complex functions are involved.
To perhaps confuse the issue, wrap this code in an anonymous, self-executing function, like this:
1 |
(function() { |
2 |
|
3 |
function foo(a, b) { |
4 |
return bar(a, b); |
5 |
}
|
6 |
|
7 |
function bar(a, b) { |
8 |
return a + b; |
9 |
}
|
10 |
|
11 |
foo(1, 2); |
12 |
|
13 |
}());
|
Wrapping code in an anonymous function is a common pattern, and at first glance it might appear this code replicates the aforementioned performance issue by wrapping the optimized code in an anonymous function. While there is a slight performance hit by executing the anonymous function, this code is perfectly acceptable. The self-executing function serves only to contain and protect the foo() and bar() functions, but more importantly, the anonymous function executes only once—thus the inner foo() and bar() functions are created only once. However, there are some cases where anonymous functions are just as (or more so) problematic as named functions.
Anonymous Functions
As far as this topic of performance is concerned, anonymous functions have the potential to be more dangerous than named functions.
It's not the anonymity of the function that is dangerous, but it's how developers use them. It's quite common to use anonymous functions when setting up event handlers, callback functions, or iterator functions. For example, the following code assigns a click event listener on the document:
1 |
document.addEventListener("click", function(evt) { |
2 |
alert("You clicked the page."); |
3 |
});
|
Here, an anonymous function is passed to the addEventListener() method to wire-up the click event on the document; so, the function executes every time the user clicks anywhere on the page. To demonstrate another common use of anonymous functions, consider this example that uses the jQuery library to select all <a /> elements in the document and iterate over them with the each() method:
1 |
$("a").each(function(index) { |
2 |
this.style.color = "red"; |
3 |
});
|
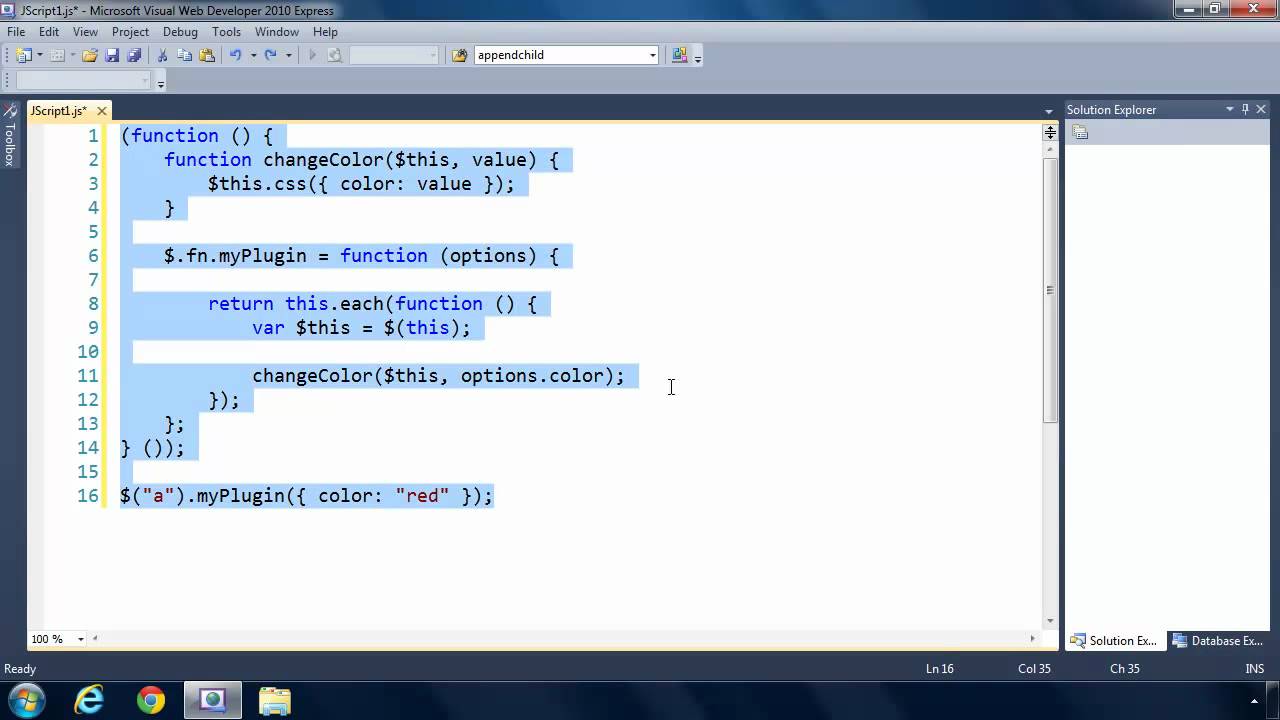
In this code, the anonymous function passed to the jQuery object's each() method executes for each <a /> element found in the document. Unlike named functions, where they are implied to be repeatedly called, the repeated execution of a large number of anonymous functions are rather explicit. It is imperative, for performance sake, that they are efficient and optimized. Take a look at the follow (yet again oversimplified) jQuery plugin:
1 |
$.fn.myPlugin = function(options) { |
2 |
|
3 |
return this.each(function() { |
4 |
var $this = $(this); |
5 |
|
6 |
function changeColor() { |
7 |
$this.css({color : options.color}); |
8 |
}
|
9 |
|
10 |
changeColor(); |
11 |
});
|
12 |
};
|
This code defines an extremely simple plugin called myPlugin; it’s so simple that many common plugin traits are absent. Normally, plugin definitions are wrapped inside self-executing anonymous functions, and usually default values are supplied for options to ensure valid data is available to use. These things have been removed for the sake of clarity.
This plugin's purpose is to change the selected elements' color to whatever is specified in the options object passed to the myPlugin() method. It does so by passing an anonymous function to the each() iterator, making this function execute for every element in the jQuery object. Inside the anonymous function, an inner function called changeColor() does the actual work of changing the element’s color. As written, this code is inefficient because, you guessed it, the changeColor() function is defined inside the iterating function... making the JavaScript engine recreate changeColor() with each iteration.
Making this code more efficient is rather simple and follows the same pattern as before: refactor the changeColor() function to be defined outside of any containing functions, and allow it to receive the information it needs to do its work. In this case, changeColor() needs the jQuery object and the new color value. The improved code looks like this:
1 |
function changeColor($obj, color) { |
2 |
$obj.css({color : color}); |
3 |
}
|
4 |
|
5 |
$.fn.myPlugin = function(options) { |
6 |
|
7 |
return this.each(function() { |
8 |
var $this = $(this); |
9 |
|
10 |
changeColor($this, options.color); |
11 |
});
|
12 |
};
|
Interestingly, this optimized code increases performance by a much smaller margin than the foo() and bar() example, with Chrome leading the pack with a 15% performance gain (jsperf.com/function-nesting-with-jquery-plugin). The truth is, accessing the DOM and using jQuery's API add their own hit to performance—especially jQuery's each(), which is notoriously slow compared to JavaScript’s native loops. But as before, keep in mind the simplicity of this example. The more nested functions, the greater the performance gain from optimization.
Nesting Functions in Constructor Functions
Another variation of this anti-pattern is nesting functions within constructors, as shown below:
1 |
function Person(firstName, lastName) { |
2 |
this.firstName = firstName; |
3 |
this.lastName = lastName; |
4 |
|
5 |
this.getFullName = function() { |
6 |
return this.firstName + " " + this.lastName; |
7 |
};
|
8 |
}
|
9 |
|
10 |
var jeremy = new Person("Jeremy", "McPeak"), |
11 |
jeffrey = new Person("Jeffrey", "Way"); |
This code defines a constructor function called Person(), and it represents (if it wasn't obvious) a person. It accepts arguments containing a person's first and last name and stores those values in firstName and lastName properties, respectively. The constructor also creates a method called getFullName(); it concatenates the firstName and lastName properties and returns the resulting string value.
When you create any object in JavaScript, the object is stored in memory
This pattern has become quite common in today's JavaScript community because it can emulate privacy, a feature that JavaScript isn't currently designed for (note that privacy isn’t in the above example; you’ll look at that later). But in using this pattern, developers create inefficiency not only in execution time, but in memory usage. When you create any object in JavaScript, the object is stored in memory. It stays in memory until all references to it are either set to null or are out of scope. In the case of the jeremy object in the above code, the function assigned to getFullName is typically stored in memory for as long as the jeremy object is in memory. When the jeffrey object is created, a new function object is created and assigned to jeffrey's getFullName member, and it too consumes memory for as long as jeffrey is in memory. The problem here is that jeremy.getFullName is a different function object than jeffrey.getFullName (jeremy.getFullName === jeffrey.getFullName results in false; run this code at http://jsfiddle.net/k9uRN/). They both have the same behavior, but they are two completely different function objects (and thus each consume memory). For clarity, take a look at Figure 1:


Here, you see the jeremy and jeffrey objects, each of which have their own getFullName() method. So, each Person object created has its own unique getFullName() method—each of which consumes its own chunk of memory. Imagine creating 100 Person objects: if each getFullName() method consumes 4KB of memory, then 100 Person objects would consume at least 400KB of memory. That can add up, but it can be drastically reduced by using the prototype object.
Use the Prototype
As mentioned earlier, functions are objects in JavaScript. All function objects have a prototype property, but it is only useful for constructor functions. In short, the prototype property is quite literally a prototype for creating objects; whatever is defined on a constructor function's prototype is shared among all objects created by that constructor function.
Unfortunately, prototypes are not stressed enough in JavaScript education.
Unfortunately, prototypes are not stressed enough in JavaScript education, yet they are absolutely essential to JavaScript because it’s based on and built with prototypes—it’s a prototypal language. Even if you never typed the word prototype in your code, they are being used behind the scenes. For example, every native string-based method, like split(), substr(), or replace(), are defined on String()'s prototype. Prototypes are so important to the JavaScript language that if you do not embrace JavaScript’s prototypal nature, you're writing inefficient code. Consider the above implementation of the Person data type: creating a Person object requires the JavaScript engine to do more work and allocate more memory.
So, how can using the prototype property make this code more efficient? Well, first take a look at the refactored code:
1 |
function Person(firstName, lastName) { |
2 |
this.firstName = firstName; |
3 |
this.lastName = lastName; |
4 |
}
|
5 |
|
6 |
Person.prototype.getFullName = function() { |
7 |
return this.firstName + " " + this.lastName; |
8 |
};
|
9 |
|
10 |
var jeremy = new Person("Jeremy", "McPeak"), |
11 |
jeffrey = new Person("Jeffrey", "Way"); |
Here, the getFullName() method definition is moved out of the constructor and onto the prototype. This simple change has the following effects:
- The constructor performs less work, and thus, executes faster (18%-96% faster). Run the test in your browser if you'd like.
- The
getFullName()method is created only once and shared among allPersonobjects (jeremy.getFullName === jeffrey.getFullNameresults intrue; run this code at http://jsfiddle.net/Pfkua/). Because of this, eachPersonobject uses less memory.
Refer back to Figure 1 and note how each object has its own getFullName() method. Now that getFullName() is defined on the prototype, the object diagram changes and is shown in Figure 2:


The jeremy and jeffrey objects no longer have their own getFullName() method, but the JavaScript engine will find it on Person()'s prototype. In older JavaScript engines, the process of finding a method on the prototype could incur a performance hit, but not so in today's JavaScript engines. The speed at which modern engines find prototyped methods is extremely fast.
Privacy
But what about privacy? After all, this anti-pattern was birthed out of a perceived need for private object members. If you’re not familiar with the pattern, take a look at the following code:
1 |
function Foo(paramOne) { |
2 |
var thisIsPrivate = paramOne; |
3 |
|
4 |
this.bar = function() { |
5 |
return thisIsPrivate; |
6 |
};
|
7 |
}
|
8 |
|
9 |
var foo = new Foo("Hello, Privacy!"); |
10 |
alert(foo.bar()); // alerts "Hello, Privacy!" |
This code defines a constructor function called Foo(), and it has one parameter called paramOne. The value passed to Foo() is stored in a local variable called thisIsPrivate. Note that thisIsPrivate is a variable, not a property; so, it is inaccessible outside of Foo(). There's also a method defined inside the constructor, and it's called bar(). Because bar() is defined within Foo(), it has access to the thisIsPrivate variable. So when you create a Foo object and call bar(), the value assigned to thisIsPrivate is returned.
The value assigned to thisIsPrivate is preserved. It cannot be accessed outside of Foo(), and thus, it is protected from outside modification. That's great, right? Well, yes and no. It's understandable why some developers want to emulate privacy in JavaScript: you can ensure that an object's data is secured from outside tampering. But at the same time, you introduce inefficiency to your code by not using the prototype.
So again, what about privacy? Well that's simple: don't do it. The language currently does not officially support private object members—although that may change in a future revision of the language. Instead of using closures to create private members, the convention to denote "private members" is to prepend the identifier with an underscore (ie: _thisIsPrivate). The following code rewrites the previous example using the convention:
1 |
function Foo(paramOne) { |
2 |
this._thisIsPrivate = paramOne; |
3 |
}
|
4 |
|
5 |
Foo.prototype.bar = function() { |
6 |
return this._thisIsPrivate; |
7 |
};
|
8 |
|
9 |
var foo = new Foo("Hello, Convention to Denote Privacy!"); |
10 |
alert(foo.bar()); // alerts "Hello, Convention to Denote Privacy!" |
No, it's not private, but the underscore convention basically says "don't touch me." Until JavaScript fully supports private properties and methods, wouldn't you rather have more efficient and performant code than privacy? The correct answer is: yes!
Summary
Where you define functions in your code impacts your application's performance; keep that in mind as you write your code. Don't nest functions inside a frequently called function. Doing so wastes CPU cycles. As for constructor functions, embrace the prototype; failure to do so results in inefficient code. After all, developers write software for users to use, and an application's performance is just as important to the user's experience as the UI.
 By
By









