


NoSQL databases have emerged tremendously in the last few years owing to their less constrained structure, scalable schema design, and faster access compared to traditional relational databases (RDBMS/SQL). MongoDB is an open-source, document-oriented NoSQL database which stores data in the form of JSON-like objects. It has emerged as one of the leading databases due to its dynamic schema, high scalability, optimal query performance, faster indexing, and active user community. In this tutorial, we will be using MongoDB as an example of a NoSQL database.
If you are coming from an RDBMS/SQL background, understanding NoSQL and MongoDB concepts can be a bit difficult while starting out because the technologies have very different manners of data representation. This article will help you understand how the RDBMS/SQL domain works and how its functionalities, terms, and query language map to a MongoDB database. By mapping, I mean that if we have a concept in RDBMS/SQL, we will see what its equivalent concept in MongoDB is.
We will start with mapping the basic relational concepts like tables, rows, columns, etc., and then we'll discuss indexing and joins. We will then look over some SQL queries and discuss their corresponding MongoDB database queries. The article assumes that you are aware of the basic relational database concepts and SQL, because throughout the article more stress will be laid on understanding how these concepts map in MongoDB. Let's begin.
Mapping Tables, Rows, and Columns
Each database in MongoDB consists of collections, which are equivalent to an RDBMS database consisting of SQL tables. Each collection stores data in the form of documents, which is equivalent to tables storing data in rows. While a row stores data in its set of columns, a document has a JSON-like structure (known as BSON in MongoDB). Lastly, we have rows in an SQL row, while we have fields in MongoDB. Here's an example of a document (row in SQL) having some fields (columns in SQL) storing user data in MongoDB:
1 |
{
|
2 |
"_id": ObjectId("5146bb52d8524270060001f3"), |
3 |
"age": 25, |
4 |
"city": "Los Angeles", |
5 |
"email": "mark@abc.com", |
6 |
"user_name": "Mark Hanks" |
7 |
}
|
This document is equivalent to a single row in RDBMS. A collection consists of many such documents, just as a table consists of many rows. Note that each document in a collection has a unique _id field, which is a 12-byte field that serves as a primary key for the documents. The field is auto-generated on creation of the document and is used to uniquely identify each document.
To understand the mappings better, let's take an example of an SQL table users and its corresponding structure in MongoDB. As shown in Figure 1, each row in the SQL table corresponds to a document and each column to a field in MongoDB.

Dynamic Schema
One interesting thing to focus on here is that different documents within a collection can have different schemas. So it's possible in MongoDB for one document to have five fields and the other document to have seven fields. The fields can be easily added, removed, and modified anytime. Also, there is no constraint on the data types of the fields. Thus, at one instance, a field can hold an int data type, and at the next instance it may hold an array data type.
These concepts might seem very different if you are coming from an RDBMS background where the table structures and their columns, data types, and relations are predefined. This functionality to use dynamic schema allows us to generate dynamic documents at run time.
For instance, consider the following two documents inside the same collection but having different schemas (Figure 2):

The first document contains the fields address and dob, which are not present in the second document, while the second document contains the fields gender and occupation, which are not present in the first one. If we had to design this schema in SQL, we would have kept four extra columns for address, dob, gender, and occupation, some of which would store empty (or null) values, hence occupying unnecessary space.
This model of dynamic schema is the reason why NoSQL databases are highly scalable in terms of design. Various complex schemas (hierarchical, tree-structured, etc.) which would require a number of RDBMS tables can be designed efficiently using such documents.
A typical example would be to store users' posts, likes, comments, and other associated information in the form of documents. An SQL implementation for the above design schema would ideally have separate tables for storing posts, comments, and likes, while a MongoDB document would store all this information in a single document.
Mapping Joins and Relationships
Relationships in RDBMS are achieved by using primary and foreign key relationships and querying those relationships using joins. There is no such straightforward mapping in MongoDB, but the relationships here are designed using embedded and linking documents.
Consider an example wherein we need to store user information and corresponding contact information. An ideal SQL design would have two tables, say user_information and contact_information, with primary keys id and contact_id, as shown in Figure 3. The contact_information table would also contain a column user_id, which would be the foreign key linking to the id field of the user_information table.

Now we will see how we would design such relationships in MongoDB using the approaches of linking documents and embedded documents. Observe that in the SQL schema, we generally add a column (like id and contact_id in our case) which acts as a primary column for that table. However, in MongoDB, we generally use the auto-generated _id field as the primary key to uniquely identify the documents.
Linking Documents
This approach will use two collections, user_information and contact_information, both having their unique _id fields. We will have a field user_id in the contact_information document which relates to the _id field of the user_information document, showing which user the contact corresponds to (see Figure 4). It is important to note that in MongoDB, the relations and their corresponding operations are usually taken care of manually (for example, through code) as no foreign key constraints and rules apply.

The user_id field in our document is simply a field that holds some data, and we have to implement all the logic associated with it. For example, even if you insert a user_id in the contact_information document that does not exist in the user_information collection, MongoDB is not going to throw any error saying that the corresponding user_id was not found in the user_information collection (unlike in SQL, where this would be an invalid foreign key constraint).
Embedding Documents
The second approach is to embed the contact_information document inside the user_information document like this (Figure 5):

In the above example, we have embedded a small document of contact information inside the user information. In a similar manner, large, complex documents and hierarchical data can be embedded like this to relate entities.
Also, the approach to use depends on the specific scenario of the design. If the data to be embedded is expected to grow larger, it is better to use the linking approach rather than the embedded approach to avoid the document becoming too large. The embedded approach is generally used in cases where a limited amount of information (like the address in our example) has to be embedded.
Mapping Chart
To summarize, the following chart (Figure 6) represents the common co-relations we have discussed:

Mapping SQL to MongoDB Queries
Now that we are comfortable with the basic mappings between RDBMS and MongoDB, we will discuss how the query language used to interact with the database differs between them.
For MongoDB queries, let's assume a collection users with a document structure as follows:
1 |
{
|
2 |
"_id": ObjectId("5146bb52d8524270060001f3"), |
3 |
"post_text":"This is a sample post" , |
4 |
"user_name": "mark", |
5 |
"post_privacy": "public", |
6 |
"post_likes_count": 0 |
7 |
}
|
For SQL queries, we assume the table users having five columns with the following structure:

We will discuss queries related to creating and altering collections (or tables), as well as inserting, reading, updating, and removing documents (or rows). There are two queries for each point, one for SQL and another for MongoDB. I will be explaining the MongoDB queries only as we are quite familiar with the SQL queries. The MongoDB queries presented here are written in the Mongo JavaScript shell, while the SQL queries are written in MySQL.
Create
In MongoDB, there is no need to explicitly create the collection structure (as we do for tables using a CREATE TABLE query). The structure of the document is automatically created when the first insert occurs in the collection. However, you can create an empty collection using the createCollection command.
1 |
SQL: CREATE TABLE `posts` (`id` int(11) NOT NULL AUTO_INCREMENT,`post_text` varchar(500) NOT NULL,`user_name` varchar(20) NOT NULL,`post_privacy` varchar(10) NOT NULL,`post_likes_count` int(11) NOT NULL,PRIMARY KEY (`id`)) |
2 |
|
3 |
MongoDB: db.createCollection("posts") |

Insert
To insert a document in MongoDB, we use the insertOne or insertMany method, which takes an object with key-value pairs as its input. The insertOne method inserts a single document, while insertMany inserts multiple documents. The inserted document will contain the auto-generated _id field. However, you can also explicitly provide a 12-byte value as the _id along with the other fields.
1 |
SQL: INSERT INTO `posts` (`id` ,`post_text` ,`user_name` ,`post_privacy` ,`post_likes_count`)VALUES (NULL , 'This is a sample post', 'mark', 'public', '0'); |
2 |
|
3 |
MongoDB: db.posts.insertOne({user_name:"mark", post_text:"This is a sample post", post_privacy:"public", post_likes_count:0}) |

It is important to note that there is no Alter Table function in MongoDB to change the document structure. As the documents are dynamic in schema, the schema changes when the document is updated.
Read
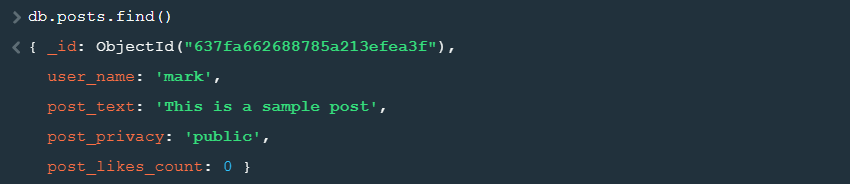
MongoDB uses the find method, which is equivalent to the SELECT command in SQL. The following statements simply read all the documents from the posts collection.
1 |
SQL: SELECT * FROM `posts` |
2 |
|
3 |
MongoDB: db.posts.find() |
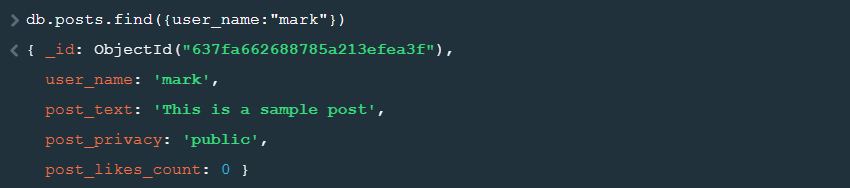
The following query does a conditional search for documents where the user_name field is mark. All the criteria for fetching the documents have to be placed in the first braces {} separated by commas.
1 |
SQL: SELECT * FROM `posts` WHERE `user_name` = 'mark' |
2 |
|
3 |
MongoDB: db.posts.find({user_name:"mark"}) |
The following query fetches specific columns, post_text and post_likes_count, as specified in the second set of braces {}.
1 |
SQL: SELECT `post_text` , `post_likes_count` FROM `posts` |
2 |
|
3 |
MongoDB: db.posts.find({},{post_text:1,post_likes_count:1}) |
Note that MongoDB by default returns the _id field with each find statement. If we do not want this field in our result set, we have to specify the _id key with a 0 value in the list of columns to be retrieved. The 0 value of the key indicates that we want to exclude this field from the result set.
1 |
MongoDB: db.posts.find({},{post_text:1,post_likes_count:1,_id:0}) |
The following query fetches specific fields based on the criterion that user_name is mark.
1 |
SQL: SELECT `post_text` , `post_likes_count` FROM `posts` WHERE `user_name` = 'mark' |
2 |
|
3 |
MongoDB: db.posts.find({user_name:"mark"},{post_text:1,post_likes_count:1}) |
We will now add one more criterion to fetch the posts with privacy type as public. The criteria fields, specified using commas, represent the logical AND condition. Thus, this statement will look for documents having both user_name as mark and post_privacy as public.
1 |
SQL: SELECT `post_text` , `post_likes_count` FROM `posts` WHERE `user_name` = 'mark' AND `post_privacy` = 'public' |
2 |
|
3 |
MongoDB: db.posts.find({user_name:"mark",post_privacy:"public"},{post_text:1,post_likes_count:1}) |
To use logical OR between the criteria in the find method, we use the $or operator.
1 |
SQL: SELECT `post_text` , `post_likes_count` FROM `posts` WHERE `user_name` = 'mark' OR `post_privacy` = 'public' |
2 |
|
3 |
MongoDB: db.posts.find({$or:[{user_name:"mark"},{post_privacy:"public"}]},{post_text:1,post_likes_count:1}) |
Next, we will use the sort method, which sorts the results in ascending order of post_likes_count (indicated by 1).
1 |
SQL: SELECT * FROM `posts` WHERE `user_name` = 'mark' order by post_likes_count ASC |
2 |
|
3 |
MongoDB: db.posts.find({user_name:"mark"}).sort({post_likes_count:1}) |
To sort the results in descending order, we specify -1 as the value of the field.
1 |
SQL: SELECT * FROM `posts` WHERE `user_name` = 'mark' order by post_likes_count DESC |
2 |
|
3 |
MongoDB: db.posts.find({user_name:"mark"}).sort({post_likes_count:-1}) |
To limit the number of documents to be returned, we use the limit method, specifying the number of documents. The query below would fetch just 10 documents as its result.
1 |
SQL: SELECT * FROM `posts` LIMIT 10 |
2 |
|
3 |
MongoDB: db.posts.find().limit(10) |
In the same way that we use offset in SQL to skip a number of records, we can use the skip function in MongoDB. For example, the following statement would fetch ten posts, skipping the first five.
1 |
SQL: SELECT * FROM `posts` LIMIT 10 OFFSET 5 |
2 |
|
3 |
MongoDB: db.posts.find().limit(10).skip(5) |
Update
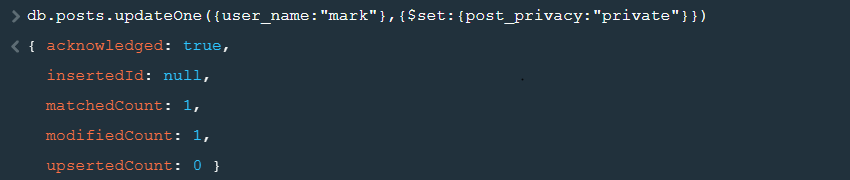
There are two methods used to update a document: updateOne is used to update a single document, while updateMany is used to update multiple documents. The first parameter for the updateOne method specifies the criteria to select the documents. The second parameter specifies the actual update operation to be performed. For example, the following query selects all the documents with user_name as mark and sets their post_privacy as private.
One difference here is that by default, the MongoDB update query updates only one (and the first matched) document. To update all the matching documents, we have to provide a third parameter specifying multi as true, indicating that we want to update multiple documents.
1 |
SQL: UPDATE posts SET post_privacy = "private" WHERE user_name='mark' |
2 |
|
3 |
MongoDB: db.posts.updateOne({user_name:"mark"},{$set:{post_privacy:"private"}}) |
Remove
Removing documents is quite simple and is similar to SQL. The query deletes all entries of the post where the username is Mark.
1 |
SQL: DELETE FROM posts WHERE user_name='mark' |
2 |
|
3 |
MongoDB: db.posts.deleteOne({user_name:"mark"}) |
Indexing
MongoDB has a default index created on the _id field of each collection. To create new indexes on the fields, we use the ensureIndex method, specifying the fields and associated sort order indicated by 1 or -1 (ascending or descending).
1 |
SQL: CREATE INDEX index_posts ON posts(user_name,post_likes_count DESC) |
2 |
|
3 |
MongoDB: db.posts.ensureIndex({user_name:1,post_likes_count:-1}) |
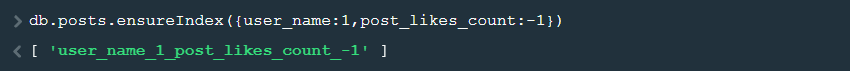
To see all the indexes present in any collection, we use the getIndexes method on the same lines of the SHOW INDEX query of SQL.
1 |
SQL: SHOW INDEX FROM posts |
2 |
|
3 |
MongoDB: db.posts.getIndexes() |

Conclusion
In this article, I explained how the elementary concepts and terms of RDBMS/SQL relate in a NoSQL database, using MongoDB as an example. We looked at designing relationships in MongoDB and learnt how the functionality of basic SQL queries map in MongoDB.
After getting a head start with this article, you can go ahead and try out complex queries including aggregation, map reduce, and queries involving multiple collections. You can also use some online tools to convert SQL queries into MongoDB queries in the beginning. You can play with designing a sample MongoDB database schema on your own. One of the best examples to do so would be a database to store user posts, likes, comments, and comment likes. This would give you a practical view of the flexible schema design that MongoDB offers.
This post has been updated with contributions from Mary Okosun. Mary is a software developer based in Lagos, Nigeria, with expertise in Node.js, JavaScript, MySQL, and NoSQL technologies.
 By
By








